When it comes to improving operational efficiency, the topic of automation often comes up. For about three decades already, even the most complex production tasks — like surface-mount technology (SMT) assembly in electronics or composite layup in aerospace manufacturing — have been performed by machines, often autonomously.
However, until recently, far fewer successful advances had been made in streamlining knowledge work: tasks that require looking up, analyzing, and synthesizing information.
Computers capable of generating human-like responses have existed since the 1960s, and business interest in chatbots peaked in the mid-2010s. Yet, early chatbots lacked the ability to hold meaningful conversations and provide value beyond answering simple questions.
The launch of ChatGPT in late 2022 once again brought conversational interfaces into the limelight, as users were amazed by the application’s cognitive powers. The subsequent hype is hard to escape, but it also somewhat conceals the actual state of adoption.
A 2024 global study by MIT Technology Review Insights (MITTR) found that although 75% of businesses have experimented with generative AI, only 9% have widely adopted the technology. Many leaders aren’t fully convinced about AI’s utility — especially when some of the biggest chatbot projects, like IBM Watson and Alexa from Amazon, have failed to live up to high expectations.
To understand the value of new generative virtual assistants and their actual capabilities, let’s take a closer look at the underlying technology.
Evolution of chatbots: From rule-based text generation to human-like cognitive capabilities
The idea of a “conversational computer” obsessed scientists (and sci-fi authors) for decades. Joseph Weizenbaum, a professor at MIT, was the pioneer. In 1966, he revealed ELIZA — the first application that “made certain kinds of natural language conversation between man and computer possible” and passed the Turing Test.
The term “chatbot” was coined in 1991 to describe TINYMUD, a real-time multiplayer game that chats with players. Both ELIZA and TINYMUD used a limited number of rules and keywords to detect and manipulate input queries, but they lacked proper contextual understanding. Users liked both (and sometimes mistook the software for real humans), but the agents’ conversational capabilities were limited.
In 1995, Richard Wallace developed an Artificial Intelligence Markup Language (AIML) to power A.L.I.C.E. — a smarter version of ELIZA. A.L.I.C.E. had about 41,000 templates and related patterns in its knowledge base, compared to ELIZA’s 200 keywords and rules. However, A.L.I.C.E. relied on pattern matching without perceiving the whole conversation, as was evident in its replies.

As the internet grew in the early 2000s, chat apps became popular, sparking renewed interest in chatbots. This time around, researchers were focused on training bots to perform simple information retrieval tasks. Launched in 2001, SmarterChild became the first chatbot capable of searching databases for information to provide weather reports, check stock prices, or get the latest sports scores.
Chatting technology improved with new techniques like probabilistic context-free grammars (PCFGs) and dependency parsing algorithms. Meanwhile, machine learning techniques like support vector machines and Naïve Bayes classifiers were adapted to text classification tasks.
In the quest to find useful applications of natural language processing (NLP) technologies, researchers switched their focus to goal-oriented dialogues, where a machine helps a human accomplish a precise task.
Cleverbot, released in 2006, was more eloquent than SmarterChild, handling free-form conversations and improving through user interactions. Commercially, businesses started adding chatbots as a marketing gimmick (you could converse with the Michelin Man on 10,000 different topics in the early 2010s!) and to streamline customer support tasks (as Alaska Airlines’ virtual assistant Jenn started doing in 2008).
In 2011, IBM unveiled Watson, the most advanced natural language processing system. Although IBM Watson understood human language well enough to win the popular Jeopardy! quiz show, it didn’t revolutionize healthcare or general business operations.
Other types of chatbots also sprung up in the 2010s: voice assistants including Siri, Cortana, and Google Assistant. These had a better understanding of natural human language and could deliver information by predicting user requirements.
Social media chatbots emerged on the Facebook (now Meta) Messenger platform, and later on another messaging app. In 2016, 54% of developers worked on chatbot projects for the first time. By the end of the year, over 34,000 chatbots had been launched for customer support, marketing, entertainment, and educational tasks.
Chatbots took over tasks like providing product information or answering support questions, but user sentiment was lukewarm. A 2019 CGS survey found that 86% of respondents preferred a human agent over a bot, and only 30% believed chatbots made issue resolution easier.
In 2021, Gartner moved “chatbots” to the trough of disillusionment stage of its Hype Cycle for Artificial Intelligence.

Source: Gartner
But while the markets cooled for natural language processing and machine learning chatbots, important research was happening in the background.
Although large language models (LLMs) and generative AI may seem new, the technology took over five years to develop.
Since the mid-2010s, computer scientists have been experimenting with techniques like generative adversarial networks (GANs), variational autoencoders (VAE), and transformers — a neural network architecture that transforms an input sequence into an output sequence by learning context and tracking relationships between sequence components.
In 2018, OpenAI published a paper showing how they had improved language understanding by combining transformers and unsupervised pre-training techniques. They called their new model the Generative Pre-trained Transformer (GPT).
GPT-1 was trained on 117 million parameters and over 4.5 GB of text from 7,000 unpublished books. Despite being computing heavy, the GPT model achieved 80% higher accuracy than typical baselines at that time.
GPT-2 1.0, released in 2019, addressed performance and stability issues with modified normalization and was trained on 1.5 billion parameters and a larger text corpus.
In May 2020, the OpenAI team published a paper about the GPT-3 model, “an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model”. GPT-3 outperformed other NLP models but wasn’t widely known to the public. Its capacity was 10 times larger than Microsoft’s Turing NLG, the next largest NLP model known at the time.
In parallel, Google’s research team was working on their own language processing architecture: Bidirectional Encoder Representations from Transformers (BERT). Introduced in 2018, BERT aimed to improve the user search experience by deciphering ambiguous queries and providing more relevant answers.
BERT and GPT, two leading large language models (LLMs), employ distinct methodologies for processing language:
- BERT (Bidirectional Encoder Representations from Transformers) uses a masked language modeling (MLM) technique. In MLM, some words in a sentence are hidden (masked), and the model’s task is to predict them based on the context provided by the other unmasked words. This process helps BERT understand the relationships among and meaning of words within sentences, enhancing its ability to handle tasks like answering questions and making language inferences.
- GPT (Generative Pre-trained Transformer), contrary to BERT’s bidirectional approach, is designed to predict the next word in a sequence in a unidirectional manner. This means GPT generates text by predicting the next word based solely on the previous words in a sequence. This autoregressive approach enables GPT to produce coherent and contextually relevant text over extended passages.
Both models build upon foundational NLP research in word representations. They leverage earlier technologies such as Stanford’s GloVe (Global Vectors for Word Representation) and Google’s Word2vec.
GloVe, introduced by Stanford in 2014, and Word2vec, developed by Google in 2013, are techniques that map words into a meaningful space where the distance between words reflects their semantic similarities. These embeddings provide a base knowledge of language from which the models can learn how to complete more complex tasks.
In November 2022, OpenAI released ChatGPT — a conversational interface for its GPT-3 model — drawing the attention of businesses to generative AI.
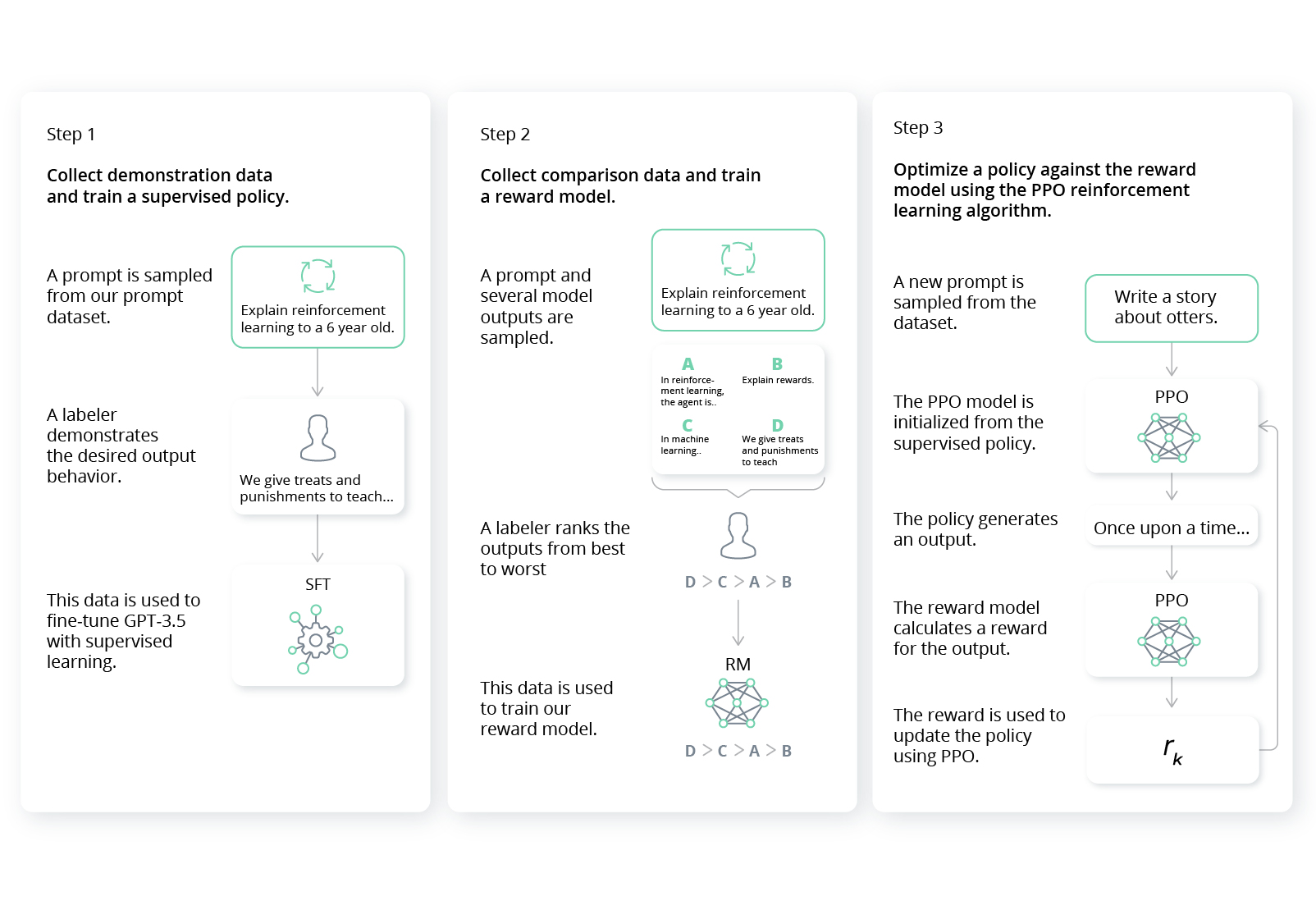
Source: OpenAI
Large language models from other big tech companies soon followed (Llama from Meta, Gemini from Google, Ernie from Baidu), as did new GenAI startups (Anthropic, Mistral, Stability AI).
The latest LLM chatbots have higher cognitive and conversational fluency than machine learning-based chatbots. The models can recognize sentiment, generate coherent replies, adapt to user prompts, and access hyper-relevant knowledge with retrieval-augmented generation (RAG).
Proposed by Meta AI, RAG is a framework for retrieving data from an external knowledge base to supply the virtual agent with the latest knowledge. Instead of retraining the model, which is a resource-intensive task, you can fine-tune it to use a specific corpus of knowledge when generating responses, such as customer support or internal policy documents.
Thanks to RAG, companies can adapt general-purpose LLMs like GPT-4 or Mixtral 8
to specific business tasks. For instance, Morgan Stanley fine-tuned OpenAI’s GPT-4 model to provide contextual answers to its workforce using data from 100,000 corporate documents. Intellias developed a GPT-enabled assistant for employee skill assessments that is capable of scanning SharePoint and LinkedIn to assemble employees’ skill profiles.
Improved language interpretation and contextual search abilities has ushered in a new era of knowledge productivity. With virtual assistants being integrated into browsers and business apps, workers can streamline a host of document management, analytics, content generation, and data management tasks.
The first chatbots only provided textual prompts and summary responses. GenAI copilots can perform tasks side by side with humans, augmenting their knowledge and productivity.
Chatbots vs GenAI virtual agents: Capabilities compared
| Chatbots | Virtual agents | |
|---|---|---|
| Response generation method |
|
|
| Contextual understanding |
|
|
| Core technologies |
|
|
| Approach to customization |
|
|
6 capabilities for GenAI virtual agents to gain a competitive advantage
Unlike machine learning chatbots, GenAI agents can perform tasks like troubleshooting code and producing a plausible business email. Instead of scanning texts for patterns, GenAI models can mimic human-like understanding of cross-domain concepts and exhibit a degree of human-like reasoning.
Effectively, virtual agents can accentuate people’s strengths and compensate for their knowledge weaknesses in certain areas, enhancing their productivity.
| Skills GenAI can enhance | Skills GenAI cannot replace |
|---|---|
| Information collection and processing | Complex problem-solving |
| Data analysis | Strategic thinking |
| Content generation | Creative visioning and direction |
| Task scheduling and prioritization | Project management |
| Written expression | Negotiation and persuasion |
| Instruction and training | Workforce planning |
Multiple sectors can achieve major productivity gains by strategically employing GenAI assistants to enhance (not replace) workers’ capabilities.
Advanced contextual search
We live in an era of rapid knowledge growth. In 1945, human knowledge doubled every 25 years; by 1982, it doubled every 12–13 months according to futurist R. Buckminster Fuller. Before the pandemic, medical knowledge doubled every eight years, but now it doubles every 73 days.
Greater data velocity and veracity don’t always translate to higher individual acumen, however. On the contrary, they cause skills to become obsolete faster. Today, people need to continuously replenish knowledge and deliver new knowledge rapidly.
Big data analytics has emerged to address this problem. Modern algorithms can analyze large volumes of data in real time to supply us with the latest information on traffic jams via Google Maps, stock prices on Yahoo, or any other detail we need to make better decisions.
AI virtual agents offer a new interface for knowledge dissemination, using pretraining and real-time access to information. AutoGPT is an open-source model that can interact with the web to perform various tasks (such as finding an email address or getting pricing on car rentals). VimGPT, based on GPT-4V, aims to teach virtual agents routine tasks like clicking buttons on an ecommerce website or subscribing to a newsletter.
While both GPTs are still in the beta stage, they already do better than voice assistants like Siri, Alexa, and Google Assistant, which can only handle the most basic actions like looking up the weather or playing the latest pop tune.
AI models excel in looking up internal information. Unlike any version of ChatGPT, an LLM chatbot powered by RAG produces hyper-relevant results by resurfacing knowledge from contracted data stores. RAG solves the problem of information scarcity that general-purpose LLMs face when asked highly specific questions in industry jargon.
For example, Google created foundation models for the healthcare industry using RAG. Morningstar used the same technique to create a workforce assistant for financial advisors. McKinsey built Lili, a GenAI search assistant, for trawling its vast coffers of corporate data.
Training an LLM from the ground up is cost-inhibitive for most companies. Fine-tuning an open-source LLM for specific data comes at a fraction of the cost. However, to benefit from GenAI models available as APIs via cloud service providers like AWS and Azure, businesses need to implement proper data architectures. This includes consolidating, categorizing, and transforming data for virtual assistants, creating reference architectures for different use cases, and ensuring model governance and security.
Data analytics
Traditional business intelligence (BI) tools commoditized access to analytics for business users, but few larger organizations established a data-driven culture. In 2019, 77% of executives admitted that adopting big data analytics and AI was a major challenge, but not for technological reasons. Rather, 93% named people and processes as the main obstacles. Missing skill sets among business users, understaffed data and analytics teams, a lack of executive support, and cultural resistance to change are well-known problems leaders struggle to resolve.
Companies needed a better interface for accessing and interpreting analytics, and GenAI appears to deliver it. In a 2024 survey from Wavestone, 43% of organizations reported to have “established a data and analytics culture,” up from 21% the year before.
Unlike traditional business intelligence apps, GenAI assistants can work with both textual and numerical data. Users can view dashboards and ask a model to look up specific numbers, find correlations between datasets, or explain data patterns.
EduTech company Zelma has created the most comprehensive student test dataset in America and enabled easy browsing using plain language. Einstein GPT by Salesforce allows users to query CRM data with text commands, while Findly created a generative AI assistant for interpreting Google 4 analytics data, as we mentioned in our post about using LLMs for data analytics tasks.
With GenAI assistants, analytics becomes more accessible and results of analysis easier to interpret, reducing the entry barrier for users and accelerating cultural transformations.
Task assistance
Arguably the most touted advantage of GenAI agents is the increase in workforce productivity they can drive. In early 2023, Nielsen Norman Group did three studies to benchmark worker productivity on tasks like resolving customer support issues, writing routine business documents, and completing simple coding projects. On average, business users’ throughput increased by 66% when using GenAI assistants.
Microsoft conducted a similar study for its Copilot, citing a 29% speed increase for routine tasks like searching, writing, and summarizing data. GitHub Copilot has also reported positive data from its users, with 88% feeling more productive and 87% saying Copilot preserves mental effort during repetitive tasks.
Copilot apps save a lot of time on menial work and help reduce the toll of context switching, and the copilot ecosystem is growing. These applications also streamline routine text and data analytics. For example, the Lyndi medical assistant can transcribe spoken conversations into EMR-ready notes, saving doctors hours of time on retyping. Sensa Copilot helps collect, summarize, and analyze data from internal and external sources about suspicious financial activity, accelerating fraud investigations by up to 70% according to its creators.
New workers benefit from GenAI systems’ programmatic guidance and tireless answering. Instead of messaging a supervisor or reading technical notes for hours, a new worker can chat with a virtual agent trained on corporate data for detailed explanations.
A recent Generative AI at Work study found that GenAI assistants help less skilled workers learn faster by showing them behavioral patterns and distilling the knowledge of more experienced peers. Likewise, an MIT working paper suggests that in mid-level professional writing tasks, “ChatGPT compresses the productivity distribution by benefiting low-ability workers more” by restructuring tasks towards idea generation and editing rather than drafting.
That said, AI copilots don’t universally lead to productivity improvements. One study found that participants performed 42% better when using GPT-4 as an assistant. But AI also had a negative effect on participants in another group whose task required more cognitive reasoning and argumentation.
“The quality improvement and decrease in performance indicates that, rather than blindly adopting AI outputs, highly skilled workers need to continue to validate AI and exert cognitive effort and expert judgment when working with AI.
Large language models can undeniably increase the velocity of completed work, but the quality of outputs can be questionable without oversight. Leaders need to prioritize workflows and use cases where copiloting adds value (for example, where it makes data more accessible or automates menial steps). Copilot systems should be vetted to avoid producing convincing falsehoods that are repeated by unsuspecting employees.
Employee training
Employee onboarding and training are time- and knowledge-intensive, requiring substantial resources. On average, businesses spend $1,280 per employee annually on training (more for specialized professions or reskilling programs).
Virtual agents can help new employees master required competencies through interactive microlearning. An LLM can be prompt-tuned on corporate procedures, processes, or product information and effectively deliver answers to new employees, like a professional trainer.
The Intellias team recently developed a product training virtual assistant for a client. Available via messengers including WhatsApp, Skype, and Telegram, the app provides sales associates with product information instantly in the form of text replies, slide decks, and product videos. The app also generates mock customer scenarios and ranks sales staff’s answers. Data about staff engagement and performance is sent to Power BI and made available as a report.
Poised has built an AI coaching app for providing real-time, personalized feedback on presentation delivery. The app detects filler words and analyzes speech confidence, energy, and empathy levels, providing personalized feedback and tips for improvement.
AI-powered employee coaching apps can enhance training efficiency and accuracy without the overhead of arranging in-person sessions in largely asynchronous and hybrid environments.
Multi-language customer support
The first chatbots struggled with non-English replies due to limited training data. GPT and other large language models also caught some slack for their improved but still limited fluency in languages other than English.
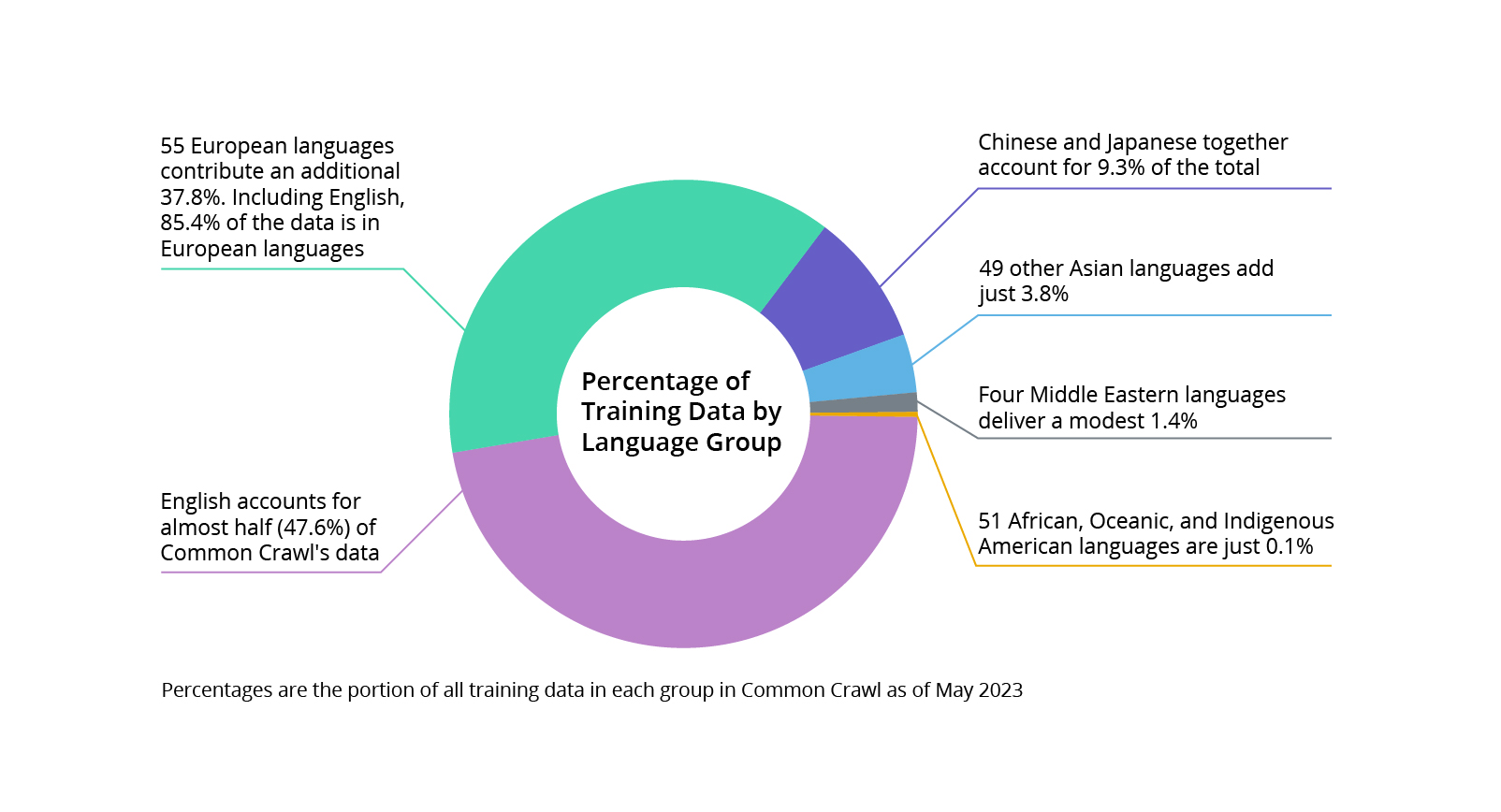
Source: CSA Research
Because many foundation models are open-source, they can be improved using various pre-training and prompt-tuning techniques. For instance, Tower — a new open multi-language model for translation tasks — offers outputs in 20 languages (including English, German, French, Spanish, Chinese, Portuguese, Italian, Russian, Korean, and Dutch) that are superior compared to larger general-purpose LLMs.
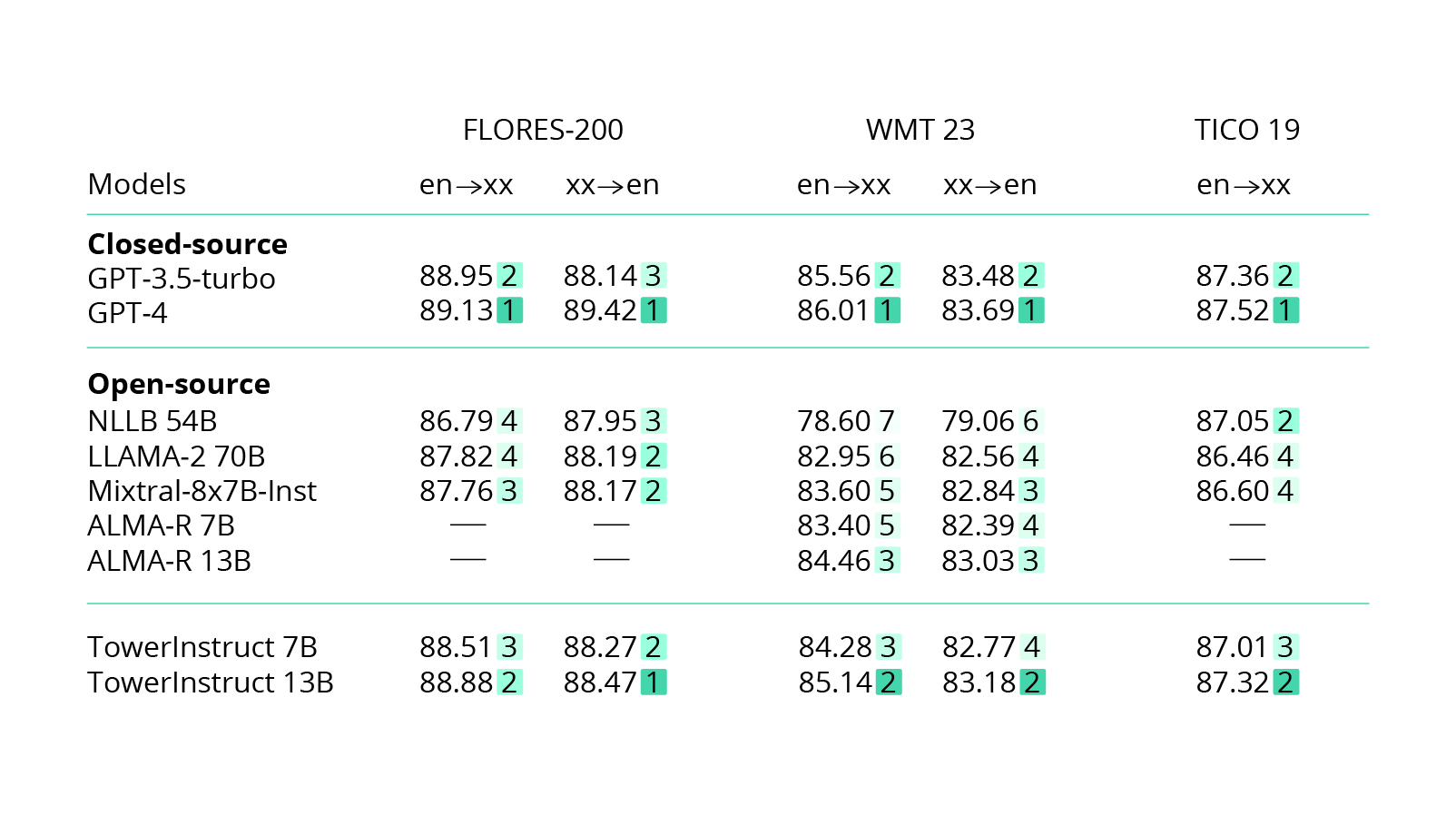
Source: arXiv
BLOOMChat, an open-source multilingual chat LLM, has achieved 42% better performance than GPT-4 across six languages in a human preference study and was preferred by 66% of human participants over a general LLM according to SambaNova.
Enhanced multi-language support improves the scale and quality of customer service. Consumers expect brand experiences in their native language and are disappointed when they are unavailable. According to Unbabel’s 2021 Global Multilingual CX study, 57% of consumers see it as biased when brands don’t offer end-to-end multilingual experiences, and 68% would switch to another brand that offers support in their native language. Multi-language LLM chatbots can eliminate language barriers and disparities by making global content visible and understandable in customers’ preferred languages.
Intellias recently helped a Fortune 500 retailer launch a GenAI assistant with multi-language support, allowing customers and sales associates to access product information in 10 languages. Integrated with Power BI, the app collects customer insights from different countries to understand buying preferences and concerns.
Image processing and generation
Last but not least, let’s not forget that GenAI goes beyond producing text. There are models for text-to-image (DALL·E), text-to-video (SORA), and text-to-audio generation (Voicebox). These can be adapted to various business use cases, from creating marketing content to creating customer service and employee training materials.
Recent advances in computer vision also promise to bring greater transformations to AI virtual agents. The first generation of computer vision apps relied on optical character recognition (OCR) to perform document digitization tasks like recognizing customer names and surnames in form fields.
The new foundation models for computer vision, like Vision Transformer (ViT), can perform advanced image recognition, object detection, and image classification tasks. For example, a vision transformer-based model delivered higher accuracy in recognizing pneumonia signs on chest X-rays than conventional methods. Embedded into a clinical decision support system, such models could provide on-demand assistance to doctors in complex cases.
The Google Research team has presented a scaled version of the ViT model with 22 billion parameters that can produce high-quality images with greater depth and detail and performs better on object recognition and detection tasks as well as on video classification. These advances in computer vision pave the way for advanced industrial robotics scenarios, especially in combination with digital twins.
With advanced computer vision models, manufacturing companies could capture visual, video, and audio data for analysis. Textual models can interpret the data and generate new visual outputs like video training materials based on actual equipment present on the production floor.
Reimagining your knowledge management system with AI agents
GenAI can help businesses incorporate knowledge that has eluded automation during earlier digitization, including unstructured data like corporate wiki entries, meeting notes, voice memos, product screenshots, and customer sales demo videos.
Most corporate data exists in silos, with few companies having curated, centralized access to shared knowledge bases. Lack of interfaces prevents 71% of companies from connecting data silos — and generative AI provides one.
By implementing scalable data architectures and connecting fine-tuned generative AI models, organizations can unlock a confluence of knowledge management use cases: digitize documents, enable contextual search, develop microtraining opportunities, and enhance data analytics.
Effectively, you can create a private knowledge management ecosystem accessible to prompt-tuned foundational models, deployed locally or with a cloud service provider. This leaves corporate data securely stored within the company’s perimeter, limiting regulatory and security risks. Standard APIs connect GenAI models to business applications and data sources, while the RAG framework ensures accurate output generation.
At every stage, we implement appropriate data governance controls to ensure data privacy, authorized use, system transparency, and reliability. By combining strong experience in data engineering and MLOps, we engineer secure, compliant, and explainable generative AI solutions designed to empower your workforce. Contact us to learn more about implementing AI virtual agents.


