Different types of AI-based solutions (machine learning, deep learning, and foundation models) are taking automation to the next level, offering both opportunities for cost savings and revenue generation. Meanwhile, AI and its “lighter” edition — machine learning — are only entering the era of productization. Although many data science teams have successfully run several pilots, far fewer have large-scale applications in production. In 2018, only 15% of enterprises had AI models in production for 5+ years, while the majority (49%) were still exploring use cases according to O’Reilly.
A 2023 survey by Insider Intelligence found that 42% of North American and 38% of EMEA companies still hadn’t adopted AI or ML or were in the research phase, while 21% and 16% (respectively) were scaling up or already had mature products.
In this post, we look at what’s holding leaders back from productizing AI and ML applications and how MLOps helps bring more pilots to production.
Why Productizing AI and Machine Learning Models Is Hard
Corporate tech budgets have been growing year over year. Gartner expects global IT spending to increase by another 8% in 2024 and reach $5.1 trillion. The hype around GenAI has also prompted some 45% of executive leaders to further increase their AI budgets. In 2023, over 60% of business leaders named applied ML among their top three priorities for the next year.
Budgets? Check. Strong buy-in? Present. So why aren’t companies progressing as much as they supposedly should with applied AI/ML?
Because of its iterative nature, the process of launching AI/ML applications differs a lot from the process of launching any other type of software.
Standard apps only include code components, while ML models are essentially a bundle of code and data. This adds new layers of complexity:
Data constraints
To produce accurate outputs, ML models require training data that is labeled, consistent, bias-free, and representative of the use case. Without a proper underlying data architecture and appropriate data governance, procuring training and validation data is hard. Acquiring accurate training data is the top challenge for 40% of ML teams. Even when appropriate data is available, it still can be off-limits due to privacy or compliance requirements. Finally, when some data is cleared for use, it still has to be transformed, labeled, and stored in a secure repository — a step that can eat up to 80% of data scientists’ time. On the upside, ML models can be created with limited datasets. Three in five tech professionals agree that the quality of training data is more important than the quantity of training data for achieving the best outcomes.
Lack of processes
The standard ML model lifecycle includes more steps compared to the application development lifecycle: data collection and processing, model development, model versioning and integration, plus ongoing model monitoring for performance, security, and effective governance.
Most of these processes are performed in an ad-hoc fashion with data scientists and operational professionals often using different tools and thus missing alignment. Over 40% of tech teams admit that their current process for developing ML models cannot be replicated for another pilot or use case. Subsequently, model development takes a tremendous amount of time and resources. Infrastructure costs run high, while deployed models fail to demonstrate ROI in production.
Lack of predictability
An ad hoc approach to ML model development creates further issues down the line. Models crash and burn before entering production due to poor (or non-existent) testing. According to various sources, data scientists shelve over 80% of ML models before even bringing them to production; only 11% of models are successfully deployed to production. And for those that are deployed, new issues emerge post-deployment. Model drift is inevitable. Explainability, auditability, security, and good governance practices become mandatory, and end-users may require tight SLAs.
That said, we’re still seeing successfully productized ML and AI models. So what do successful teams do differently? They rely on building a strong machine learning operations (MLOps) process.
What is MLOps?
MLOps is a set of practices and standardized workflows for creating a repeatable, continuous, and automated process for building and deploying machine learning models. Effectively, MLOps service adapts certain DevOps best practices like continuous integration (CI), version control, and pipeline automation to the realities of developing different ML (Machine Learning), DL (Deep Learning), and AI (Artificial Intelligence) solutions.
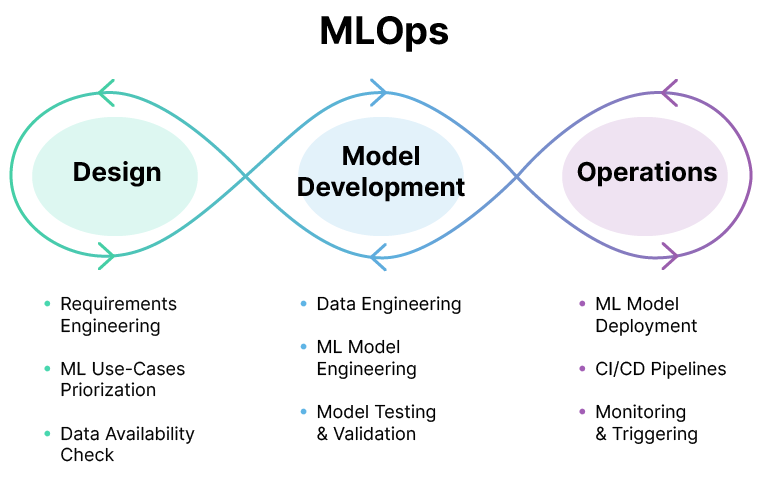
Source: MLOps.org
The concept of MLOps was originally conceptualized by Google researchers in the now-classic paper “Hidden Technical Debt in Machine Learning Systems.” This paper describes at great length all the machine learning model development issues the team was facing:
- Lack of abstraction boundaries and data dependencies, which made it hard to modify code without changing the model behavior
- Unstable dependencies between different data sets, which resulted in decaying model performance over time
- Rapidly stitched together data pipelines, which turn into a pipeline jungle without proper tending
- Configuration debt accumulated through a series of successful (and failed) deployment attempts
In 2018, two Googlers gave a great talk at SREcon APAC about productizing machine learning models, and many of their ideas got picked up and polished by the growing data science community. Later in the year, Jeremy Lewi and David Aronchick, also from Google, released Kubeflow — the first semi-comprehensive platform for machine learning pipeline creation and workflow orchestration on Kubernetes. Fast forward to today, when MLOps is the go-to framework leading ML and AI development teams use to consolidate and automate all key steps in machine learning model development into one continuous, repeatable, and streamlined master workflow.
In 2022, 85% of companies had a dedicated budget for MLOps, with 98% planning to further increase their investments by at least 11% and 58% — by over 25%.
How MLOps differs from DevOps
MLOps and DevOps pursue the same goal: creating a repeatable, fault-tolerant workflow for deploying new products. The difference is that DevOps focuses on new code deployments and management, while MLOps handles code + data deployment (aka new ML models). Compared to DevOps, the standard MLOps lifecycle incorporates extra steps specific to deploying, monitoring, and retraining models.
DevOps emphasizes code quality through continuous testing. MLOps focuses on data quality instead. The framework implements extra steps to ensure data availability, quality, versioning, and traceability — factors that are critical for ensuring model accuracy, explainability, and security.
Similar to DevOps, MLOps promotes the creation of continuous feedback loops, but for machine learning models. In practice, this includes streamlined model validation and continuous monitoring, aimed at detecting and preventing model glitches. For example, you can set up alerts for different model events (such as a decline in accuracy) with Azure Event Grid and then program remediation actions (for example, injecting new training data).
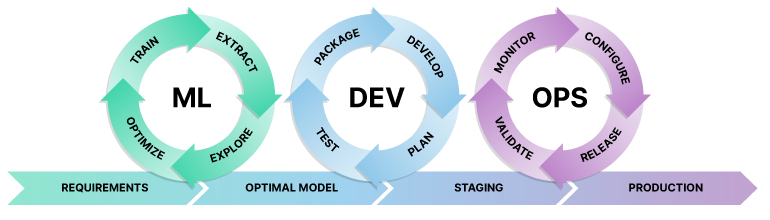
On the other hand, DevOps and MLOps have a different approach to automated deployments. New ML models, trained offline, cannot be deployed to production in one click. You need multi-step pipelines, which call upon auxiliary services including a model registry and a model monitoring service.
Culturally, MLOps was designed for hybrid teams of software engineers, data scientists, and operations professionals. Typically, data scientists have experience with data analysis, model development, and experiment tracking, but they’re not experienced in converting these to consumer-ready products. Hence, software engineers need to step in, while operations professionals help to determine proper infrastructure configuration and automate resource provisioning for deploying new models. Fundamentally, MLOps borrows and adapts DevOps best practices to the machine learning model lifecycle, infusing greater predictability into the process of bringing new ML/DL solutions to life and ensuring their longevity in production environments.
Comparison of key MLOps vs DevOps practices
| DevOps | MLOps | |
|---|---|---|
| Continuous Integration (CI) | Streamlined validation and testing of code and software components | Streamlined validation and testing of code/components, plus data, data schemes, and models |
| Continuous Deployment (CD) | One-step pipeline for (semi)automated deployment of new software packages | Multi-step pipeline for deploying an ML system (code, data, model monitoring/prediction service) |
| Continuous Testing (CT) | Automated code validation at different stages of the pipeline | Automated retraining and re-serving of new models |
| Continuous Monitoring (CM) | Ongoing monitoring of compliance issues and security threats during each phase of the DevOps pipeline; CM can also be extended to IT infrastructure monitoring | Ongoing monitoring of production data and model performance metrics connected to business metrics |
Key MLOps principles
Automation
MLOps promotes automation on three levels:
- Manual processes such as data cleansing or metadata management are the first candidates for automation. They’re traditionally error-prone and time-consuming. Automated data processing pipelines help avoid redundant data preprocessing and make data sets accessible to all consumers. Jupyter, for example, offers a convenient development environment for ML models with handy automation tools.
- ML pipeline automation assumes the automation of model training and retraining. In this case, your pipeline includes triggers for auto-active model retraining to avoid model concept drifts or loss of relevance in its outputs. Triggers can be time-based (weekly/monthly) or event-based (when new training data becomes available or performance degrades). This level of MLOps maturity assumes prior automation of data prep and management steps.
- CI/CD pipeline automation. At the highest level of MLOps maturity, teams can rapidly and reliably deploy new models to production. With CI/CD pipeline automation, you can implement capabilities to automatically build, test, and deploy data, models, and ML training pipeline components.
Reproducibility
The goal of reproducibility is to ensure that ML models and their associated data can be easily replicated across different stages of the model lifecycle (data processing, model training) and across various production environments.
Best practices for ensuring model reproducibility include:
- Following proper data versioning and regular backup practices
- Replicating data set snapshots across storage locations
- Ensuring clear data lineage and ownership structures
- Maintaining the same order of features during model training
- Documenting and automating feature transformation and hyperparameter selection
- Ensuring consistency in software versions and dependencies between training and production environments
Unlike standard software products, machine learning models can generate multiple code branches during the development and training stages, meaning there’s more code (and data) to log, store, and version control. Moreover, models generate multiple artifacts (reports, vocabularies, etc.) during the training stage that also need to be documented and versioned to ensure reproducibility. MLOps addresses both issues with automated version control and automated metadata management.

Versioning
Versioning is a key enabler of reproducibility. ML model development is a highly interactive process, with data scientists constantly experimenting with hyperparameters or feature transformations to get better (or worse) outputs. Models also evolve when new training data becomes available and you need the ability to roll back to a previous serving version if there are performance issues.
By tracking ML models and data sets with version control systems, the versioning process ensures that all model elements are properly documented and thus can be replicated if needed. For example, DVC offers a storage-agnostic version control system designed specifically for ML projects. Git can also be adapted for versioning of ML workflows. With versioning tools in place, each new model training session will create a corresponding file with all metadata that can be (auto)-committed to version control. Afterward, anyone can reproduce your training or the entire ML pipeline. The ML metadata store can also record relevant information about ML pipeline execution to enhance reproducibility, track errors, and identify anomalies.
Monitoring
Validating model accuracy and validity against predefined metrics is critical for ensuring high model accuracy. ML models are prone to concept drift over time. As predictions become less accurate due to changes in market data, your algorithm needs to be retrained. However, noticing the exact moment of model degradation isn’t easy. MLOps Community states that most ML teams (72%) require a week or more to detect and fix a model performance issue.
Typical timeframe for model issue detection and resolution by ML teams
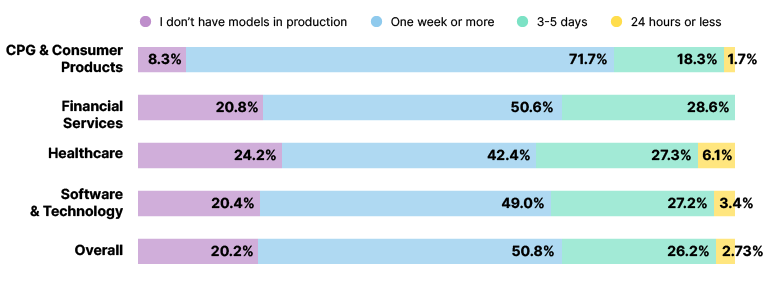
Source: MLOps Community — Survey: The Industry Is Ready for ML Observability At Scale.
It’s best to automate model monitoring and set up automatic alerts and triggers for retraining. Mature MLOps teams monitor several types of parameters, including:
- Dependency changes throughout the complete pipeline (data version changes, dependency upgrades, etc.) that can indicate possible performance issues.
- Data invariants in training and serving inputs (e.g., mismatches in the data schema), which may hinder the training process.
- Computational performance of the ML system (GPU memory use, network traffic, etc.), as anomalies in computational performance often indicate underlying issues.
- Model performance degradation on served data. Model performance drift can happen due to changes in data or monitored conditions. Early detection means faster remediation.
Tools like MLWatcher, Grafana, and Prometheus (among others) let you monitor performance and data anomalies, track model accuracy and predictions, and detect concept drift.
Business impact and benefits of MLOps
MLOps standardizes and streamlines a host of operational steps in new model development. In practice, adopting MLOps means that:
- New machine learning models are developed based on available data and validated use cases rather than in a purely ad hoc, exploratory manner.
- Data scientists have access to premade, versioned, and cleansed datasets for model training, validation, and ongoing performance monitoring.
- Operations professionals can easily deploy new models alongside the services that wrap and consume them as part of a unified release process.
- Most manual tasks related to data collection, computing resource management, experiment tracking, and model monitoring in production are automated to a large extent.
The impact of these changes is quite massive, both money- and time-wise.
MLOps foundation expected outcomes to reduce platform, people, and operation costs
| Business goal | Technical metric | Before MLOps | MLOps expected outcomes | Business value |
|---|---|---|---|---|
| Be more efficient in delivery | Time to value (from idea to production) | up to 12 months | < 3 months | Improve speed-to-value by 4x |
| Simplify route-to-live | Time to productionize existing ML use cases | 3 – 6 months | < 2 weeks | Reduce FTE overhead in average 8x |
| Standardize infrastructure, data, and code | % template driven development | n/a | > 85% | Focus on innovation increasing re-usability by 85% |
| Standardize onboarding of new teams and ML use cases | Time to instantiate a new MLOps infrastructure & ML projects | 40 days | < 1 hours | Accelerate ML adoption across all business areas |
| Ensure high security standards | Execute the ML solutions without internet access in a private cloud | n/a | No internet | Your data is safe in your private cloud |
Source: AWS
Development efficiency and speed
MLOps simplifies the process of moving ML models from development to deployment, reducing the time to market for new products.
On average, machine learning teams spend seven months to deploy one machine learning project to production according to Comet. Extended time-to-market not only delays potential benefits but also increases model development costs, as prolonged development cycles lead to inefficient use of resources and missed opportunities for value creation. Mature MLOps teams, in contrast, spend less than a month deploying a new model from idea to production. Intellias, for example, recently demonstrated this efficiency by setting up an MLOps framework for a fleet management software provider, rapidly operationalizing telemetry data from trucks.
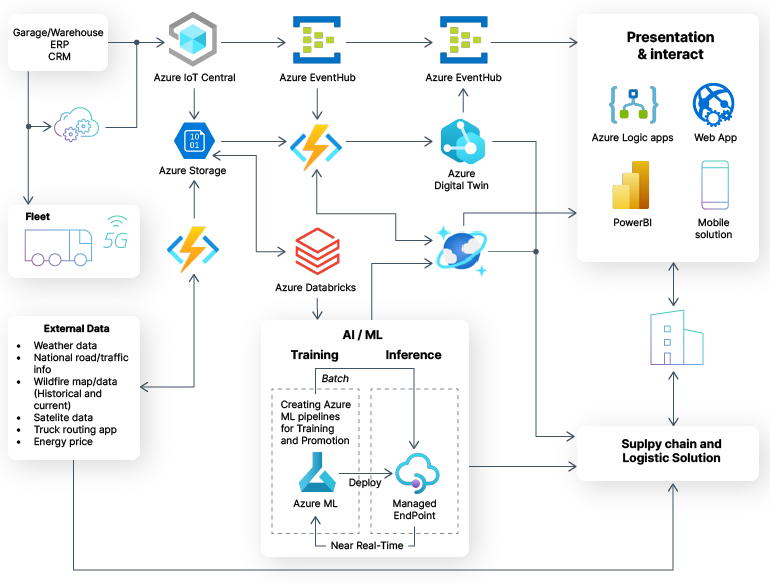
With the new infrastructure in place, the company can effectively collect fleet telematics data from on-board systems and IoT devices and securely store it in cloud repositories. Available data is automatically ingested into a digital twin system for real-time fleet monitoring — and the company’s ML team can access the transformed insights to run ad hoc analysis and develop new custom ML models, plus deploy these to production.
Better quality assurance
Almost half (46%) of ML teams name lack of data quality or precision as the main reason for project failures. An automated data transformation process coupled with a model validation step helps prevent such scenarios at the development stage. Ongoing model monitoring, in turn, helps detect and fix performance issues in production.
Automated model monitoring is also critical for addressing two other significant issues:
- Model edge cases
- Concept drift
As the model gets exposed to new data, edge cases emerge — unusual outliers in data due to its complexity or variability. Edge cases are hard to predict during the training stage because they’re rare in training data. Nonetheless, they can negatively impact model accuracy in production or, on the contrary, indicate new customer use cases. Monitoring tools help identify such anomalies and prompt your team to investigate them further.
Concept drift, in turn, occurs when statistical parameters of analyzed conditions change over time. For example, changes in customer behavior can render an existing predictive model less effective.
The ability to detect and address model drift is critical for ensuring high end-user satisfaction and preventing biased model results.
The Intellias AI team recently helped a client develop a generative AI chat agent that provides up-to-date sustainability data on the company’s operations. With a monitoring stack, we can accurately measure the AI agent’s performance in real time and initiate its retraining based on customer feedback, changes in customer inquiries, or updates to the underlying datasets.
Higher scalability
More and more industries are eager to adopt and productize AI, including agriculture, finance, travel, telecommunications, and transportation.
AI-driven spending will climb 20% to 25% over the next year, outpacing expectations for a modest increase in IT budgets.
MLOps practices are essential to ensure faster, more effective development of new ML, DL, GenAI, and foundation models. In organizations with mature MLOP practices, 54% of AI projects successfully make it from pilot to production — and 40% of organizations report having hundreds of AI/ML models deployed according to Gartner.
The digital bank Revolut deployed a machine learning model for fraud detection and prevention in just nine months using MLOps best practices. The system, nicknamed Sherlock, runs on a fully serverless architecture on Google Cloud Platform.
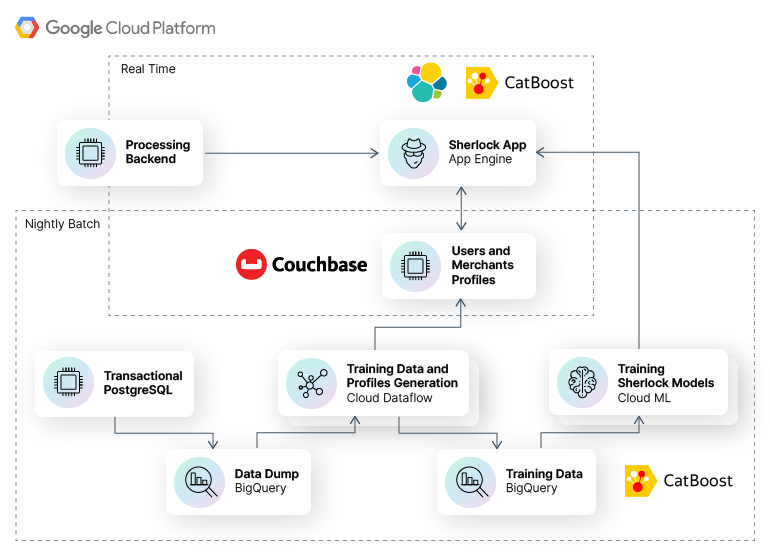
Source: Medium — Building a state-of-the-art card fraud detection system in 9 months
Revolut sends all card transactions to Sherlock Flask, which is deployed on the Google Cloud App Engine. Machine learning models are then preloaded into memory. When the Sherlock app receives an HTTP POST request for a transaction, it fetches Couchbase profiles for the corresponding user and merchant. Then the system generates a feature vector — using the same features created in the Apache Beam job based on the training data — to make a prediction. Next, the prediction gets dispatched as a JSON response to the processing back end, where an action is taken (e.g., a transaction is blocked or authorized). All of this happens within 50 milliseconds across billions of user transactions.
Improved operational decision-making
MLOps is more than just a set of tech practices — it’s a cultural shift, helping to bridge the gap between technical and business stakeholders. Thanks to better process standardization and precise monitoring, MLOps helps engineers provide comparable benchmarks on model performance to justify further investments as well as quantify the value of different models.
Business leaders, in turn, get more information about the benefits, risks, and ROI of different AI use cases and can make more informed decisions. The Total Economic Study of the Red Hat Cloud MLOps platform, for example, reported on the following quantifiable ROI based on analyzed customer case studies:
- 20% time savings for data scientists thanks to a better toolkit, standardized workflows, and self-service tools for infrastructure configuration
- 60% time savings for software developers thanks to the implementation of CI/CD tools and automatic infrastructure provisioning
- 60% time savings on infrastructure operations tasks with self-service tools and process standardization
- 30% savings on infrastructure costs thanks to better configurations and smarter ML workflow orchestration
Effectively, MLOps facilitates tighter integration between technical strategies and business goals, paving the way for more strategic collaborations and measurable ROI.
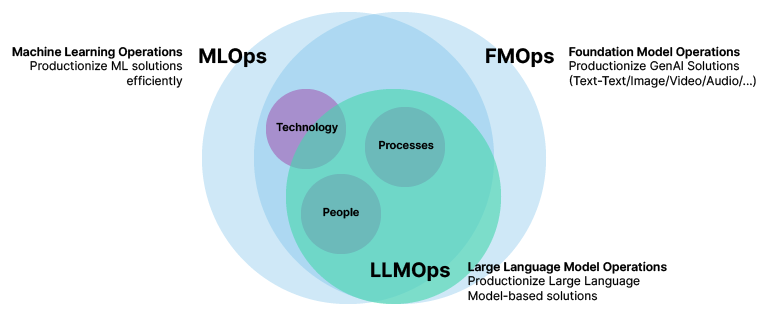
The next phase: MLOps for LLMs and foundation models
Source: AWS
MLOps was originally designed for supervised and unsupervised machine learning models. However, leaders now have a growing appetite to productize generative AI components, namely:
- Foundation models — text-to-text, text-to-image, and text-to-audio solutions
- Large language models (LLMs) — models showing general-purpose language understanding and new language generation
GenAI models consume much more training data and rely on billions of parameters for decision-making. The ChatGPT-3 model was trained on 570 gigabytes of text and 175 billion parameters. Subsequent releases have been even more resource-hungry.
The operational logic of such systems also differs from ML models, since they require a prompt engineering step on the back end, for example, and input/output rating from users on the front end. If you want to develop or embed an LLM or a foundation model, you will need to adapt your development process.
The key elements of LLMOps are:
- Data management: Data ingestion, cleaning, labeling, and storage in the data lake
- Model development: Model selection from a registry, fine-tuning, and evaluation
- Model deployment: Monitoring and performance optimization.
- Security and privacy: Guardrails, access controls, data encryption, and compliance
Sample MLOps framework for Gen AI applications
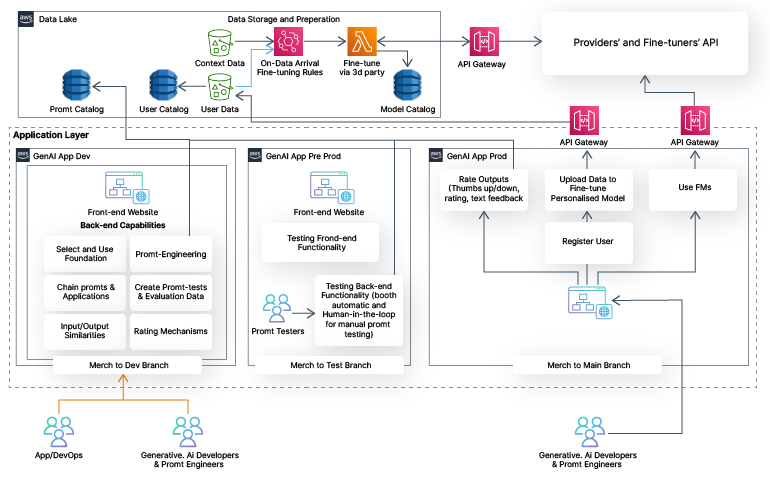
Source: AWS
Generative AI apps can be deployed with CI/CD pipelines as illustrated in the diagram above by calling a pretrained model via an API, then testing the application and promoting the deployment to a pre-production environment where the model is further tested by prompt engineers. With all tests completed, the model can be merged with the main code branch via CI/CD.
Implementing MLOps with Intellias
By 2030, AI can contribute over $15.7 trillion to the global economy. MLOps will be a key component for enabling successful model development, predictable deployments, and scaling in production — all sustained over time thanks to CI/CD.
Intellias is helping global businesses demonstrate ROI from ML and AI models through expert technology guidance, use case evaluation, and hands-on support with productizing ML models. Our AI/ML team can help convert your data into intelligence, create smart predictive systems, establish processes for smooth data ingestion and management, and enable continuous model refining and monitoring. Contact us to discuss how we can help you infuse artificial intelligence and machine learning into your products to capture operational savings and unlock new revenue streams.


