We are living through the data big bang, in which the number of bytes of data we collectively create is a 30-digit number. This is good, as data is the raw material for innovation — so long as we can harness, systematize, and analyze it. What makes mastering colossal data streams possible is artificial intelligence. Hardly anything can digest these enormous piles of data to derive meaningful information as quickly as artificial intelligence (AI) algorithms.
But what data are algorithms going to analyze? How much? What for? In 2016, the European Union adopted a regulation that answers these questions to some extent. However, it is also a game-changer for AI and machine learning (ML) development.
- In this article, you’ll learn about:
- What we can create by combining data and AI
- Why the GDPR affects AI development
- The main challenges which arise due to GDPR and machine learning limitations
- The combo of EU AI Act, GDPR and generative AI
- The impact of GDPR and AI Act on businesses
- How to develop GDPR-friendly artificial intelligence
What can we create by combining data and AI?
By leveraging the capabilities of AI and ML, tech companies and research institutions make new materials, discover drugs, detect fraud, protect crops, and so on. In our daily lives, we face AI algorithms, too — from email filters to personalized product offerings and music suggestions to digital assistants.
Another prominent result of AI and data synergy is smart city technology that aims at addressing common urban issues, such as optimizing traffic and parking, managing emergencies, preventing vandalism, and ensuring public safety. In other words, it aims to create social harmony through technology.
An example of smart city technology is the social credit scoring system being implemented in China. The country’s government uses an AI-powered system capable of comparing vast amounts of data with official databases and developing knowledge based on this analysis. Most of the data is gathered from traditional sources such as financial, criminal, and government records, registry offices, and third-party sources such as online credit platforms.
Systems like the Chinese social credit scoring system do bring benefits for citizens and make urban services more efficient. However, such vast access to data raises concerns about privacy, bias, and political interference. The alliance of AI and big data has brought data subjects’ privacy rights and freedoms to the table.
How does the GDPR impact AI and machine learning?
While China was expanding the use of personal data for urban governance, the European Union was passing regulations to limit data use.
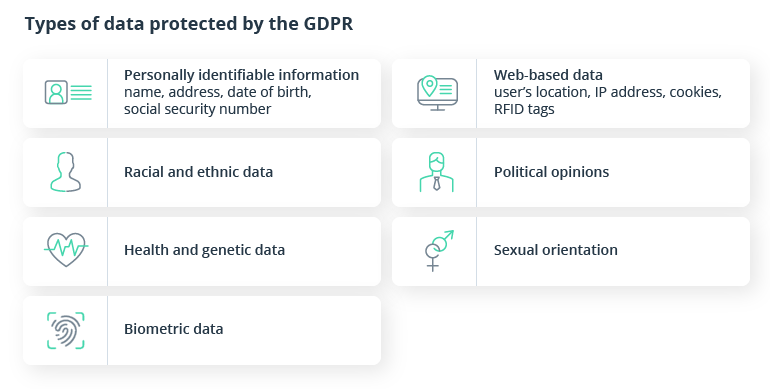
The European Union adopted a Data Protection Directive long before people started to share their data online. And after years of discussions and preparations, the European Parliament replaced this directive by adopting the General Data Protection Regulation in May 2016. With the GDPR, the EU aimed to harmonize data privacy laws across all its member countries, safeguard data being transferred abroad, and provide individuals with more control over their personal data. The GDPR sets high standards for privacy and applies to data that, either alone or in combination with other data, can identify a person.
By setting clear guidelines for data protection, the European Union fosters innovation and economic growth. Companies are encouraged to develop new, privacy-centric technologies and business models, which can lead to new opportunities and market growth.
The EU’s data protection laws have a global impact. The GDPR has been the starting point for data protection laws in countries outside the EU and in individual US states. For example, the California Consumer Privacy Act was signed in June 2018, becoming the first data privacy act in the US. This extraterritorial effect has led many non-EU countries to adopt similar standards, effectively raising the bar for data protection worldwide.
The GDPR went into force in May 2018, affecting Europe-based companies and all companies processing and holding the personal data of those residing in the EU. The tech industry took issue with the stringent rules, as the regulation touches on the two main pillars of artificial intelligence and machine learning.
First, it enhances data security, as AI and data privacy always come together. The GDPR poses strict obligations on companies that collect and process any personal data. Most AI-based systems require large volumes of information to train and learn from. Usually, personal data is among these training datasets. The GDPR’s impact on AI and machine learning development is inevitable.
Second, the regulation explicitly addresses “automated individual decision-making” and profiling. According to Article 22, a person has a right not to be subject to either if they produce legal effects concerning him or her. Automated individual decision-making here covers an AI’s decisions made without any human intervention. Profiling means the automated processing of personal data to evaluate certain things about the data subject. For instance, an AI system might analyze a user’s credit card history to identify the user’s spending patterns.
What challenges arise from GDPR limitations on AI?
The GDPR has six data protection principles at its core. According to a report by the Norwegian Data Protection Authority, artificial intelligence and data protection face four challenges associated with these principles.
- Fairness and discrimination
The GDPR fairness principle addresses fair processing of personal data. In other words, data must be processed with respect for the data subject’s interests. Also, the regulation obligates that a data controller take measures to prevent discriminatory effects on individuals. It’s no secret that many AI systems are trained using biased data. Or that their algorithmic models contain certain biases. That’s why AI systems often demonstrate racial, gender, health, religious, or ideological discrimination. For GDPR compliance using AI, companies have to learn how to mitigate those biases in their AI systems.
- Purpose limitation
The purpose limitation principle of the GDPR states that a data subject has to be informed about the purpose of data collection and processing. Only then can a person choose whether to consent to the processing. The interesting thing is that sometimes AI systems use information that’s a side product of the original data collection. For instance, an AI application can use social media data for calculating a user’s insurance rate. The GDPR states that data can be processed further if the further purpose is compatible with the original. If it isn’t, the data collector should get additional approval from the data subject. But this principle has a few exceptions.
Further data processing is always compatible with the previous purpose if it’s connected to scientific, historical, or statistical research. Herein lies a problem, since there’s no clear definition of scientific research. This means that in some cases, AI development may be considered such research. The rule of thumb is that when the AI model is static and already deployed, the purpose of its data collection can’t be regarded as research.
- Data minimization
The GDPR data minimization principle controls the degree of intervention into a data subject’s privacy. It ensures that data collected fits the purpose of the project. Collected information should be adequate, limited, and relevant. These requirements encourage developers to think through the application of their AI models. Engineers have to determine what data and what quantity of it is necessary for a project. Sometimes, this can be a challenge. It’s not always possible to predict how and what a model will learn from data. Developers should continuously reassess the type of and minimum quantity of training data required to fulfil the data minimization principle.
- Transparency and the right to information
The GDPR aims to ensure that individuals have the power to decide which of their information is used by third parties. This means that data controllers have to be open and transparent about their actions. They should provide a detailed description of what they’re doing with personal information to the owners of that information. Unfortunately, with AI systems, this may be hard to do.
That’s because AI is essentially a black box. It’s not always clear how the model makes decisions. Which makes it impossible to explain an AI’s complicated processes to an everyday user. Naturally, when AI is not entirely transparent, the question of liability arises.
According to the GDPR and AI, a data subject has the right to an explanation of an automated decision. So data controllers have to figure out ways to give one.
Navigating the EU AI Act’s View of Generative AI
The European Union wants to lead the way with responsible AI by introducing a comprehensive legal framework to regulate the ethical use of artificial intelligence. The EU AI Act emphasizes reducing bias and ensuring human control over automation. The directive aims to ensure that AI systems are safe, transparent, and respect EU standards on fundamental rights and values. The framework could impact AI use as significantly as the GDPR affected personal data processing.
Who will be affected by the new EU AI regulations?
Essentially, most businesses will be.
These regulations will likely impact any business that uses AI, including companies based in or operating within the EU that work with AI or use AI-embedded components. Even companies not developing their own AI systems, but using systems with AI components, must comply with the new rules.
The emergence of generative AI has brought forward significant challenges in ensuring the quality, reliability, and ethical use of its outputs. The EU AI Act is poised to address these challenges by categorizing AI systems based on their risk level. This law directly impacts generative AI technologies, like ChatGPT or deepfakes, requiring compliance with the requirements, including clear disclosure that content has been artificially created.
The EU AI Act mandates transparency for AI systems that interact with humans and create text, images, videos, and other types of content. The AI Act could require generative AI applications to use high-quality and ethically sourced data, ensuring the respect of data protection laws, especially GDPR. The EU emphasizes the ethical use of data, aligning with GDPR principles. AI companies will need to ensure that their generative models are trained on ethically sourced, non-biased, and GDPR-compliant datasets.
Generative AI models should be designed to prevent them from producing illegal content. All copyrighted data used for training AI algorithms should be published in summaries. High-risk AI models used for general purpose, such as GPT-4, would be thoroughly evaluated.
Since the Act ensures that high-risk generative AI systems adhere to strict standards for data quality and human oversight, posing new challenges to AI companies:
- Addressing and mitigating biases in generative AI models, ensuring fair and non-discriminatory outputs.
- Navigating complex intellectual property issues, as generative AI challenges traditional concepts of authorship and copyright.
- Increasing operational costs to comply with new regulations.
- Staying agile and responsive to evolving regulations, maintaining competitiveness and innovation in the AI domain.
In 2024, Intellias announced a strategic partnership with 2021.AI, a key player in applied AI technology, to navigate the challenges presented by the EU AI Act’s focus on high-risk systems and its potential impact on innovation. This alliance will help address the issues enterprises face in adopting AI technologies.
Intellias and 2021.AI will cooperate to build technology-centric Governance, Risk, and Compliance (GRC) solutions that will help businesses adhere to evolving regulations. These solutions will offer an effective approach to meeting standards and foster AI-driven innovation within the dynamic landscape.
GRACE, the flagship AI platform from 2021.AI, is renowned for its ability to expedite AI implementations while providing comprehensive GRC support. Its features, including automated impact assessments, a flexible rules engine, and a robust AI validation and certification process, are integral to simplifying regulatory compliance. This aligns seamlessly with Intellias’ commitment to delivering streamlined, high-impact technology solutions. Together, Intellias and 2021.AI are poised to guide businesses through the complexities of the EU AI Act, ensuring that innovation continues to thrive under the new regulatory.

How to develop GDPR-friendly artificial intelligence
Like it or not, IT companies have to ensure all their processes are compliant with the GDPR. Data processors and data controllers who violate this regulation will have to pay significant fines. Luckily, there are several ways of making AI compliant with the GDPR. Take a look at these GDPR-friendly methods of AI development.
We need to find a way to design and use machine learning algorithms in a way that is compliant with the GDPR, because they will generate value for both service providers and data subjects if done correctly.
GANs (Generative Adversarial Networks). Today, the trend in AI development is to use less data more efficiently rather than to accumulate lots of data. A GAN reduces the need for training data by generating input data with the help of output data. Basically, with this method, we take the input and try to figure out what the output will look like. To achieve this, we need to train two neural networks: a generator and a discriminator.
The generator learns how to put data together to generate an image that resembles the output. The discriminator learns how to tell the difference between real data and the data produced by the generator. The problem here is that GANs still require lots of data to be trained properly. So this method doesn’t eliminate the need for training data; it just allows us to reduce the amount of initial data and generate a lot of similar augmented data. But if we use a small number of initial datasets, we risk getting a biased AI model in the end. So generative adversarial neural networks don’t solve these issues fully, though they do allow us to decrease the need for initial data.
Federated learning is another method of reducing the need for data in AI development. Remarkably, it doesn’t require collecting data at all. In federated learning, personal data doesn’t leave the system that stores it. It’s never collected or uploaded to an AI’s computers. With federated learning, an AI model trains locally on each system with local data. Later, the trained model merges with the master model as an update. But the problem is that a locally trained AI model is limited, since it’s personalized. And even if no data leaves the device, the model is still largely based on personal data. Unfortunately, this contradicts the GDPR’s transparency principle.
The AI model is personalized on the user’s phone. All the training data remains on the device and is not uploaded to the cloud.
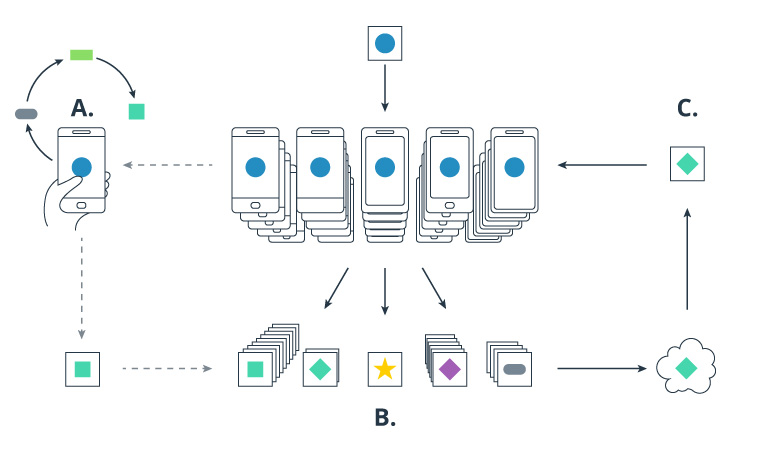
Source: AI Google Blog
Transfer learning is a method that enables the effective reuse of prior work and leads to the democratization of artificial intelligence. In this case, the AI model doesn’t train from scratch. Instead, it takes an existing model and retrains itself using it to meet the current purpose. Since the AI model uses a pre-existing model, it takes significantly less computing resources and requires less data. But transfer learning works best when the previous model has been trained on a large dataset. Also, the previous model has to be reliable and not contain any biases. So transfer learning can minimize data use but doesn’t exclude the need for data fully.
The explainable AI (XAI) method helps to reduce the black box effect of artificial intelligence. The goal of explainable AI is to assist humans in understanding what’s happening under the hood of an AI system. With this method, an AI model can explain its decisions. It can also characterize its own abilities and give some insights about its future behavior. Explainable AI cannot directly reduce the need for data, but it allows us to understand which exact data is required to enhance model accuracy so researchers can extend the training dataset with required data only and not add a lot of meaningless data.
XAI concept
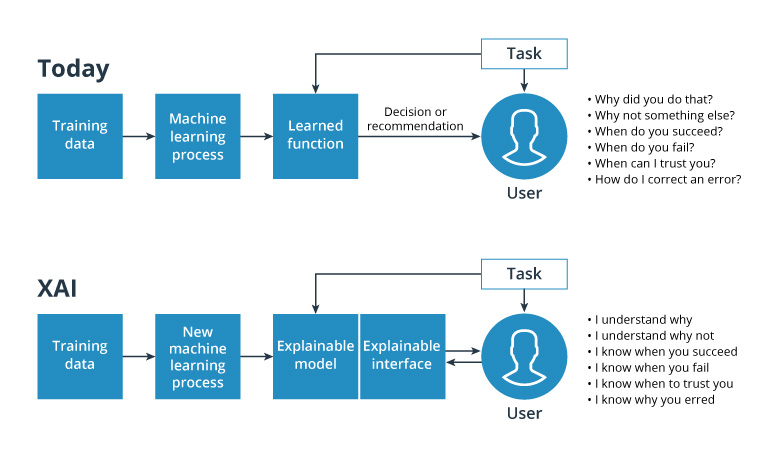
Source: Darpa
The simple truth is that all of these AI training methods we’ve mentioned are somewhat limited. They may comply with one GDPR principle but contradict another. This means that to train AI models properly and achieve great results, you’ll have to combine several methods.
Summing up
The synergy of AI/ML and data can be of tremendous benefit to individuals and society, but organizations using AI systems must address the risks for data privacy rights and freedoms. To do that, AI market players should bring together the GDPR and AI regulation. The importance of balancing innovation, data privacy, and ethical considerations in AI development lies in ensuring sustainable technological progress while safeguarding individual rights and societal norms.
Innovation drives advancements and economic growth, but without ethical guidelines and a data privacy regulator, AI technologies can lead to data breaches, biased decision-making, and loss of trust. Thus, tech companies have to revise their data privacy and artificial intelligence policies. Data controllers have to ensure that their AI systems don’t violate the regulation. Luckily, there are several methods of making AI compliant with GDPR. GANs, XAI, federated learning, transfer learning, and differential privacy can help you develop a GDPR-friendly artificial intelligence system.
EU GDPR and AI Act-compliant systems can increase user trust and safety, as these regulations ensure robust data protection and ethical AI practices. Compliance fosters transparency and accountability in AI operations, leading to more reliable technology.
Contact Intellias to create more responsible and user-centric AI solutions that are viable in a global market and compliant to GDPR and EU AI Act standards.



