From a technical standpoint, a payment transaction is some unit of work performed in distributed systems. Every database transaction has ACID properties – they are atomic, consistent, isolated and durable. But when it comes to payments, transactional consistency means that a transaction can go through without any issues (even if the user messed up something).
Here’s a quick example to illustrate this point: You are PSP (payment service provider) such as PayPal. Some user wants to send $25 to an eBay seller. So when the person clicks that “pay” button, several things happen behind the hood:
- The user transaction gets registered in the system.
- The system proxies this transaction request to acquiring bank.
- And then it patiently waits for notification from the bank that the transaction went through alright.
But then things suddenly go awry. Instead of one notification, we got two:
- One from the bank stating that the transaction was processed.
- Another one from our system saying that the user clicked the cancel button during processing or hit page refresh (or otherwise interfered with the process).

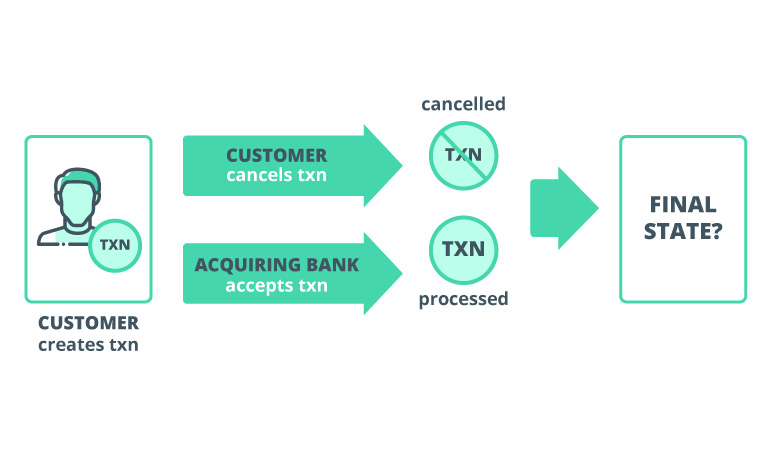
Now there’s a problem: we have a transaction that’s, at the same time, processed and cancelled. Here you go – that’s a prime example of payment transaction inconsistency.
But now we need to figure out which one is correct. And that’s somewhat challenging as those two actions were processed in parallel.
When we don’t have a guarantee of consistency in our system, we can have acid in databases but still not have strong consistency guarantee in distributed systems. As a result, we have a three-way inconsistency between our system, customer and acquiring bank.
The technical fix: transaction locking
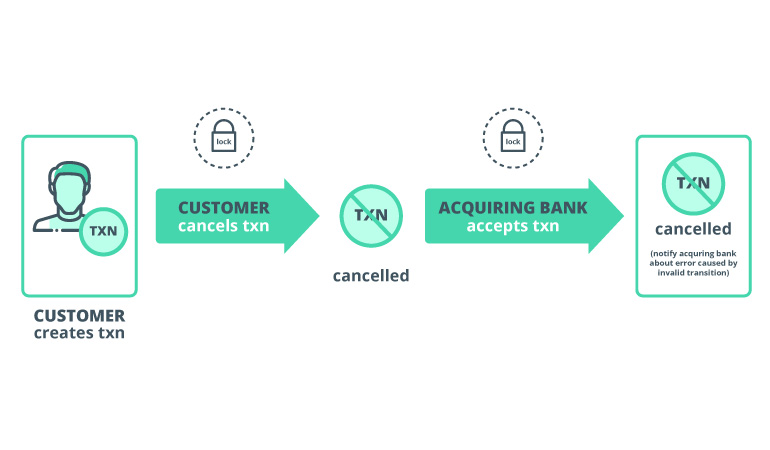
To solve this conundrum, we can do one great thing: apply a lock on transaction entity when we perform any operation with it. Locking gives us the guarantee that only one action can be processed at any given time.
If that’s the case, here’s how the previous scenario would unroll: after the user hits cancel, we place a lock on transaction to cancel it. At the same time, the bank gets in line to process that transaction. After it acquired lock to proceed, our system already knows that the transaction is cancelled. So we send that info to the bank and it rolls back the transaction.
Everyone’s happy.
Now let’s move on to the technical part of this post: a quick case study showing exactly how distributed locks can be applied towards payment transactions to ensure consistency.
How to use distributed locks to achieve data consistency in payment processing
Let’s define how to implement distributed locks with .NET Core and Apache ZooKeeper and how to ensure payment data consistency. But first, here are some key terms first, we’ll be using in this case study.
What’s a distributed lock?
A distributed lock is just a primitive that allows different processes operate with shared resources in mutually exclusive way inside a distributed environment. So, basically, it’s the same locks we use in scope of operating systems but designed to work in a distributed environment.
Why do we need distributed locks?
For two good reasons:
Efficiency: adding a lock means that no piece of work is done twice, which may result in minor errors in the system – executing scheduled jobs, processing some events like user registration and activation, and we’ll not use more computing resources that we need. Hence, our system is effective and fast.
Consistency: If processing the same piece of work simultaneously can result in corrupted data, locking can help prevent its execution (as illustrated in the example above).
What does a CAP theorem have to do with all of that?
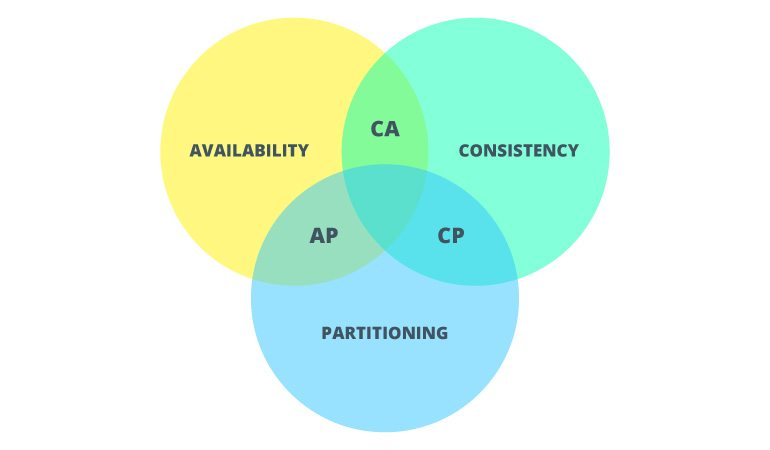
A CAP theorem is the fundamental part to distributed systems. It says:
In the presence of a network partition, one has to choose between consistency and availability.
In other words, if we want to design a fault-tolerant distributed system, we can only ensure high tolerance across two out of three system properties:
- C – consistency
- A – availability
- P – partition
Source: Towards Data Science
In the case with distributed locks, we are mostly interested in Consistency property. We want all nodes in our distributed system to observe the same data at the same time. So the most recent read operation executed on any node of the system will return the result of the most recent write operation.
Basic distributed lock implementation using Apache ZooKeeper and .NET Core
So, why are we going with ZooKeeper?
It has one neat advantage over other solutions. ZooKeeper doesn’t expose API calls to create, acquire, and release locks directly. Instead, it exposes a file system-like API, consisting of a smaller set of calls, that enables applications to implement their own primitives.
The ZooKeeper API exposes the following operations:
- create /path data — Creates a znode named with /path and containing data
- delete /path — Deletes the znode /path
- exists /path — Checks whether /path exists
- setData /path data — Sets the data of znode /path to data
- getData /path — Returns the data in /path
- getChildren /path — Returns the list of children under /path
Additionally, ZooKeeper already comes with attractive ZK recipes functionality:
- ZK recipes allow you to build different custom usage patterns and primitives for your distributed system.
- Or, you can use pre-made recipes that are shipped with Apache Curator for Java.
Now let’s move on to practicalities.
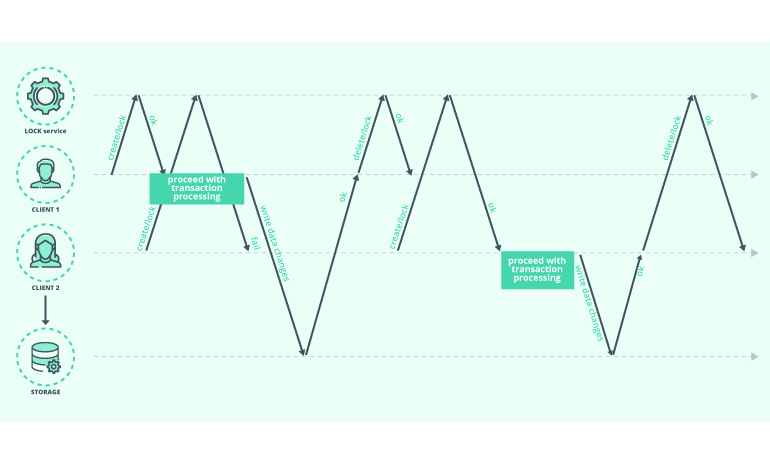
The basic lock implementation happens the following way:
- To acquire the lock, each process will try to create a znode (let’s call it /lock)
- If process 1 (P1) succeeds in creating znode, the lock is acquired
- The P1 will proceed with the execution of code
- Process 2 (P2) will need to set a watch on this znode and try to repeat the process if a znode is removed until it succeeds in acquiring the lock.
Source: Martin Kleppmann – How to Do Distributed Locking?
The biggest problem at this point is releasing the lock. So what if something goes wrong with P1? Will we end up with a deadlock?
No one wants that. So we’ll have to make znode ephemeral. In that case, if client P1 will lose connection to ZooKeeper service, the lock will be automatically released.
This approach can help fix lock release, but we’ll still have some issues with the way watches are implemented in ZooKeeper.
ZooKeeper triggers all watches set for a znode when a change occurs. So for instance, if we try to acquire the lock from 1000 processes, every time the lock will be released, ZooKeeper will trigger some 1000 notifications. And this notifications’ spike can increase latency for calls submitted at that time.
We can avoid this scenario by using sequential znodes. Each ++-process will create sequential znode /lock/lock-. ZooKeeper will automatically give each znode a sequence number. Using this number, we’ll determine which process acquired the lock (aka znode with lowest sequence number).
The processes that didn’t get the lock will set the watch on the closest znode. This way we’ll have just one watch set for each znode and avoid the herd effect.
So far, so good. We’ve just implemented one of the recipes described in ZooKeeper documentation. And it does look like a bulletproof recipe for a distributed lock.
But are things always that simple with distributed systems? Nah.
Picture this:
- One transaction got the lock during step 3, znode name “lock/lock-0”, as described in recipe documentation.
- Another transaction process created znode “lock/lock-1” and activated the watch on “lock/lock-0”.
- Some network latency crept into the connection between the first process and ZooKeeper. That process fails to send a heartbeat to ZooKeeper. As a result, the service marks the session as expired, but the process can’t receive that “session expired” notification before it reconnects. In such cases, the process will proceed with executing the code under the critical section.
- The second process receives a notification about node “lock/lock-0” removal and successfully acquires the lock.
- As a result, two processes hold the lock simultaneously.
And there you have a breach in the consistency rule stating that “two clients cannot think that they hold the same lock”.
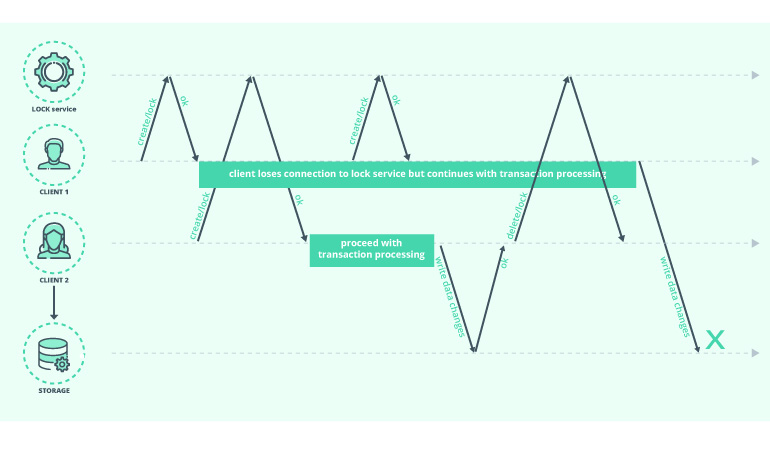
Source: Martin Kleppmann – How to Do Distributed Locking?
Connectivity issues are not the only reason why such a thing can happen. It could also result from a high CPU load. Or a page fault generated while reading from memory due to slow disk I/O.
In any case, let’s take a look at how we can fix things up.
How to implement fencing token functionally to further improve consistency
A fencing token is simply unique and strictly increasing number, which we store along with the data changes in a storage layer.
When it’s in use, the storage layer will not be able to write a request using a token that is smaller than the other ones associated with the stored data. So the code can only perform and succeed with performing the write only if the fencing token is larger than the current one.
Here’s what we can do in ZooKeeper to implement a fencing token.
- When we create znode, we get back a Stat structure, czxid member of which is zxid of the created node.
- And we can use it as fencing token because it’s guaranteed to be monotonically increasing.
Any requests that change the state of ZooKeeper are forwarded to the leader, who executes the request by producing a transaction. The leader assigns an identifier (zxid) to the transaction. And then those identifiers are applied to the state of servers in the order established by the leader.
Now showcase time. Here’s how I implemented this lock primitive constructor using .NET Core and ZooKeeperNetEx nuget package.
A quick note on why I’m using this package: a) it supports .NET Core and async model, while the package recommended by Apache ZooKeeper is a bit outdated and has no support for read-only connections:
public interface IExclusiveLock : IDisposable
{
Task<(bool result, bool owner, long fencingToken, CancellationToken cancellationToken)> Wait(bool acquireLockOnConnectionFail = true);
Task Release();
}
public ExclusiveLock(string connectionString, string lockPath, int connectTimeoutMs, CancellationToken cancellationToken, ILogger logger)
P.S. Check my GitHub for the entire implementation example.
Now we can pass the parameter named “acquireLockOnConnectionFail” which will force eventual consistency in the system. What it does is this: if the process encounters any connection issues while attempting to acquire a lock and this parameter is true, the lock would still be acquired successfully.
For return parameters we have:
- result – indicates if the lock was successfully acquired or not
- owner – this parameter tells us if we waited for the lock to be released by another process. If the parameter is returned as false, we can decide to not run code under the critical section, because another process already acquired and released the lock. This parameter can be used for the optimization of concurrent long-running tasks.
- fencingToken – czxid returned by ZooKeeper is used for this.
- cancellationToken – set in case when SessionExpired notification arrives from ZooKeeper service, or the lock acquire takes longer then passed timeout, or if the cancellation token passed while creating a lock object is set.
Why should you create a custom distributed look?
After all, there’s already a ready-to-use package that provides lock implementation recommended by ZooKeeper documentation. So why bother?
Well, there are a few solid reasons for that:
- That package does not provide you with a fencing token
- There is no way of setting up a timeout for the entire process of acquiring the lock. You can only set the connection timeout for the client.
- There is no way to cancel acquiring of the lock from calling code.
Additionally, in this specific case, I needed to accomplish several other things:
- Optimize the system for the long-running processes, which I implemented using owner parameter in response.
- Establish a simple way for forcing eventual consistency from calling code. So if we encounter any troubles with ZooKeeper service, we can proceed with processing, even if we now that something can go wrong.
Wrapping it up
To finish this case study, I’d also like to share a few extra tips for getting things right with ZooKeeper:
- Always use an odd number of nodes. This will help optimize the resources used by cluster, allowing you to set up the size of a quorum, sufficient in case of a split brain.
- Opt for hosts with fast drives. Faster drives = faster transaction processing by nodes.
- Disable swap on hosts. ZooKeeper is a Java app. Disabling swap will help you troubleshoot strange ensemble behavior as when GC will kick in and try to load some pages from hard drives. And when high I/O slows down GC to the point that other nodes in your setup will think that this node is down.
- And, obviously, network connectivity. The better connection you have, the faster everything will run.
In case you still have questions or need expert help with achieving data consistency in payment processing, do not hesitate to contact us. Our specialists will help you ace the subject.



