Gone are the days when you could squeeze virtually all data management practices into a single database administrator’s job description. We have a different relationship with data now. It’s central to developing strategies, optimizing operations, enhancing customer experiences, and driving business growth overall.
Companies collect and produce a staggering (and ever-growing) amount of structured and unstructured data. Corporate data storage has largely migrated to the cloud, which supports extreme performance and complexity, in turn enabling companies to store and use more data. Databases evolved into data warehouses, data lakes, data fabrics, and data meshes to address the growing need for ultra-fast data aggregation and instant, always-on availability.
Your typical data engineering strategy now requires a variety of roles:
- Data engineers
- Data analysts
- Data scientists
According to a recent report from Allied Market Research, companies lack skilled engineers with a modern approach to data engineering. This makes it hard for businesses to leverage their data and build an effective data engineering roadmap. We’ve seen this issue with many clients.
For example, Intellias recently helped a national telecom provider migrate to the cloud to optimize its data infrastructure. The client had been handling hundreds of terabytes of data in a legacy system, leading to multiple inefficiencies and increased costs. Our qualified engineers helped the company reduce data processing time and CPU load, resulting in a more efficient system.
Read on to learn more about the required steps to build a data engineering strategy, the industry’s best practices, and how our engineers can help.
Importance of a Data Engineering Strategy
Experts estimate the global big data implementation and data engineering market will hit the $169.9 billion mark by 2029. That makes sense since to develop intelligent systems like high-frequency trading platforms, predictive analytics, and personalized recommendation engines, you need modern and efficient big data analytics systems.
Data engineering strategy isn’t just about cutting-edge solutions for large enterprises, either. Midmarket businesses often consume vast amounts of data from external systems, field teams, IoT sensor arrays, user inputs, and more.

Source: ResearchGate
As companies grow, the number of data sources and data types they need to manage multiplies. It gets increasingly difficult to process all this incoming data without delays or data loss. To mitigate these issues, you’ll need to come up with a detailed strategy for data engineering in big data.
Implementing modern data engineering principles in your strategy has many benefits:
- Enhanced data management. Optimizing data management ensures you avoid losing valuable insights, so you find all growth opportunities. Having the right specialists, tools, and infrastructure is critical to managing large data volumes effectively.
- Efficient data integration. Integrating data efficiently helps you prevent inconsistencies and maintain integrity across multiple sources. If your data is integrated correctly, it will be easy to extract meaningful insights and make data-driven decisions.
- Improved data warehousing. Traditional data warehousing systems can’t handle modern volumes, so cloud solutions are better in efficiency and scalability. As a technology partner of Microsoft, AWS, and Google Cloud, Intellias can help you set up a reliable data warehouse on any of the major cloud platforms.
- Better decision-making. It’s essential that businesses can extract data insights quickly and easily to seize all growth opportunities. For example, Intellias helped a transportation company make cost-optimizing decisions by predicting fleet behavior and forecasting traffic.
Big data engineers use their in-depth knowledge, understanding of distributed and scalable cloud systems, and various specialized tools to create a data implementation strategy. They build high-performance data pipelines that consolidate data, transform it according to predefined rules, and then send it to designated storage destinations. After that, the ball is in the court of data analysts and data scientists.
A big data engineer can use different technologies and tools depending on your business needs:

It’s important to understand that tools alone don’t get the job done. Ensuring an uninterrupted flow of data, its automatic conversion, and transformation requires a wide outlook on the business needs of the company and a thorough understanding of its infrastructure.
It also requires an ability to construct a flexible and scalable framework feeding perfectly structured, clean data outside. Additionally, it is typically assumed that data engineers are responsible for data security, integrity, and the overall support and maintenance of the pipeline.
All of the above, combined, makes the job of a data engineer a vital element of any company’s big data engineering strategy. A recent LinkedIn job market report which placed Artificial Intelligence Engineers as 10th on the list of the most popular emerging jobs demonstrates the importance of big data engineering across industries.
10 steps to implement a data engineering strategy
The experts at Intellias have created dozens of strategies for data engineering solutions across various sectors. Based on that experience, here’s how to build a data engineering strategy from scratch for your business:
1. Identify Challenges
Start building your data engineering strategy by identifying and understanding the challenges faced by your company. While your challenges may vary depending on your project, these three are incredibly common:
- Scalability: Checking whether you can handle growing data volumes without performance loss
- Integration: Ensuring the consistency of your data from different sources
- Quality: Making sure your data is accurate and reliable.
The experts at Intellias always begin their data engineering services by identifying challenges and conducting preliminary research. Properly scoping the project is one of the most important data engineering best practices to reduce extra costs and optimize all processes along the way.
Ask yourself the following questions:
- What data should you keep, and what should you delete?
- What platforms will you use?
- How will you organize the data: data warehouse, data lake, data fabric, or data mesh?
- How will you process the data: in batches or in real-time streams?
- Where will you store the data: in the cloud or on local infrastructure?
- How will you cleanse and integrate the data?
Answering these questions will help you get a full understanding of how to implement a data engineering strategy in your company. Also consider your needs for backups, data quality audits, security assessments, and performance reviews.
2. Choose the right tools
Choose the best tools and frameworks depending on your pipelines’ complexity and requirements:
- Off-the-shelf tools: Workflow automation tools like Apache Airflow or Azkaban;
- Custom approaches: Custom solutions built on frameworks like Apache Airflow for more complex needs;
- Programming languages: Python for scripting and automation.
The right technologies are essential to your big data strategy. They help you launch the digital transformation process faster and assess your needs during the early stages so you can make adjustments. Your data stack may also include large language models and data analytics tools.
3. Monitor data channels
You’ll have to develop methods to monitor data channels and capture incoming data. Consider these elements in your data operations:
- Data monitoring: Track data flow and detect issues with tools like Prometheus and Grafana.
- Format handling: Capture data in various formats from different sources using the ELK stack or Apache Kafka.
- Real-time capture: Ensure data is captured in real-time with a tool like Prometheus or Datadog.
Effective monitoring is essential for maintaining the integrity of your data pipeline. You can also use other tools depending on your expertise and needs, but these are some of the most popular choices.
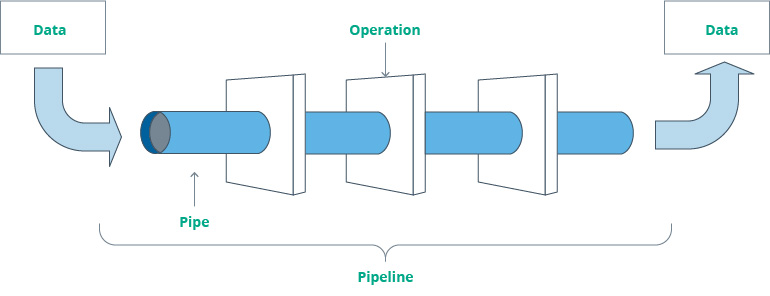
4. Transform and convert data
Convert and transform data to match the format and schema of the target destination. You’ll have to use several data engineering techniques for this step:
- Data transformation: Use ETL processes to transform data into the required format with tools like Apache NiFi, Apache Ray, or Dask.
- Schema matching: Ensure data conforms to the schema of the destination by using schema registry services like Confluent Schema Registry.
- Automation: Automate transformation processes with scripting languages like Python or Scala, applying frameworks such as Apache Airflow or Prefect to orchestrate and manage complex workflows. Proper transformation and conversion will help you integrate data seamlessly into your ETL pipeline. It will also ensure everything meets the required standards.
Automation: Automate transformation processes with scripting languages like Python or Scala, applying frameworks such as Apache Airflow or Prefect to orchestrate and manage complex workflows. Proper transformation and conversion will help you integrate data seamlessly into your ETL pipeline. It will also ensure everything meets the required standards.
If you’re serious about big data, you’ll want to integrate DataOps practices into your approach. Check out our guide on the importance of DataOps to learn what DataOps is and how it’s revolutionizing big data in engineering.
5. Save to target destinations
Store the processed data in the target destination. You have a variety of options:
- Data warehouses: Choose from platforms like Amazon Redshift, Google BigQuery, or Snowflake for structured data storage and fast querying.
- Data lakes: Consider scalable cloud storage solutions such as Amazon S3 or Azure Data Lake for storing unstructured, raw data.
- Database management: Get efficient database management with PostgreSQL or MySQL. Also, use tools like Apache Hudi or Delta Lake for data versioning and incremental updates.
- Data mesh: Decentralize data ownership and use tools like Starburst to enable teams to share data products across the organization.
- Data fabric:Unify data management across complex or hybrid data infrastructure with solutions like IBM Data Fabric or Talend Data Fabric.
It’s important to know the differences between a data warehouse and a data lake to understand how they work. Some key points to remember:
- Data warehouse: A centralized repository for structured data used for reporting and analysis
- Schema-on-write: Data is written according to predefined schemas using tools like ETL
- Structured data: Primarily used for fast access to historical data with platforms like Snowflake
- Read-only mode: Data remains in a read-only state for analysis, ensuring data integrity and performance
- Data lake: a place to keep unstructured, raw data in scalable cloud storage.
- Schema-on-read: Data is read without predefined schemas using tools like Apache Hadoop
- Flexibility: Offers flexibility to users and systems accessing the data, suitable for various analytics tasks
- Native format storage: Data is stored in its original format, simplifying analysis with platforms like AWS Lake Formation
Intellias always suggests creating a system that is accessible, actionable, and visible across the organization. This helps avoid unnecessary data silos and ensures that everyone can find and use the data they need.
6. Handle schema changes
Change is inevitable, so you’ll need to create mechanisms to handle changes in data schemas and business logic efficiently. Your data structures and their defined rules will need to adjust to new fields, types, names, and relationships. Be prepared to handle these changes with strategies such as:
- Schema modifications: Tools like Avro or Protobuf are great for managing evolving schemas and ensuring backward compatibility.
- Business logic: Data build tools can help you implement changes in business logic with transformation adjustments and validation rules.
- Automation: Data engineering automation tools like Jenkins or GitLab CI help by automating schema updates and validation processes with CI/CD pipelines.
This will help you get additional flexibility and maintain data accuracy. Also, automating schema changes minimizes downtime and ensures that data pipelines continue to function smoothly, even as underlying data structures evolve.
7. Maintain and optimize
Regularly maintain and optimize your data pipelines for performance and reliability to ensure smooth and efficient operations. The best practices in data engineering depend on the following factors:
- Pipeline maintenance: Perform regular checks and updates using tools like Apache Airflow to automate maintenance tasks and ensure that all components of a pipeline are functioning correctly.
- Performance optimization: Use performance monitoring tools such as New Relic or Grafana to identify bottlenecks and potential spots for improvement.
- Error handling: Implement error detection and correction mechanisms with logging frameworks like Logstash to capture and analyze error logs, and set up automated alerts to notify your team in real time and establish clear error-resolving workflows.
- Scalability: Ensure your pipeline can scale according to your increasing data volumes and complexity by choosing elastic cloud storage solutions like GCP, AWS, and Azure.
Timely maintenance and optimization are necessary to prevent bottlenecks and let your data flow without obstacles. This will help your company get all insights on time with no delays.
9. Balance costs and resources
Your budget isn’t infinite, so you’ll have to manage costs effectively. Follow these points to minimize expenses and get the most value in return:
- Cost management: Balance spending on storage and compute resources with cloud platforms like Google Cloud, AWS, and Azure.
- Scalable Solutions: Use scalable cloud storage for cost-effective data management, so you only pay for what you use.
- Resource allocation: Optimize resource allocation using tools like Kubernetes for dynamic resource management.
There are many ways to save your budget from extra costs. However, it takes technical experience and expertise to define these opportunities and maintain maximum value. For example, Intellias helped Germany’s first fully digital bank set up a cost-efficient and effective data lake platform. Our platform development experts will help you get all the best solutions for your project.
10. Partner with professionals
You’ll need a reliable team of data engineers with expertise in your product’s industry. After all, you’re trusting them to follow all these steps and help your business build a reliable solution that brings valuable results.
The professionals at Intellias have 20+ years of experience in the market. Our expertise spans cloud-native architectures for rapid deployment and management of next-generation data infrastructures, ensuring operational efficiency and cost savings while minimizing errors through transparent, AI-driven decision-making processes.
Best practices of big data engineering
Following the industry’s data engineering best practices is key to creating high-quality data solutions in any company. We gathered the most valuable practices based on the experience of our engineers.
1. Modular approach
Modularity involves designing data systems as discrete modules, each addressing specific problems. Segregate datasets into modules based on their use or category to enhance data management. This approach simplifies code readability, reusability, and testing. Modular systems are easier to maintain, and make it easier for new team members to quickly understand and contribute to the project.
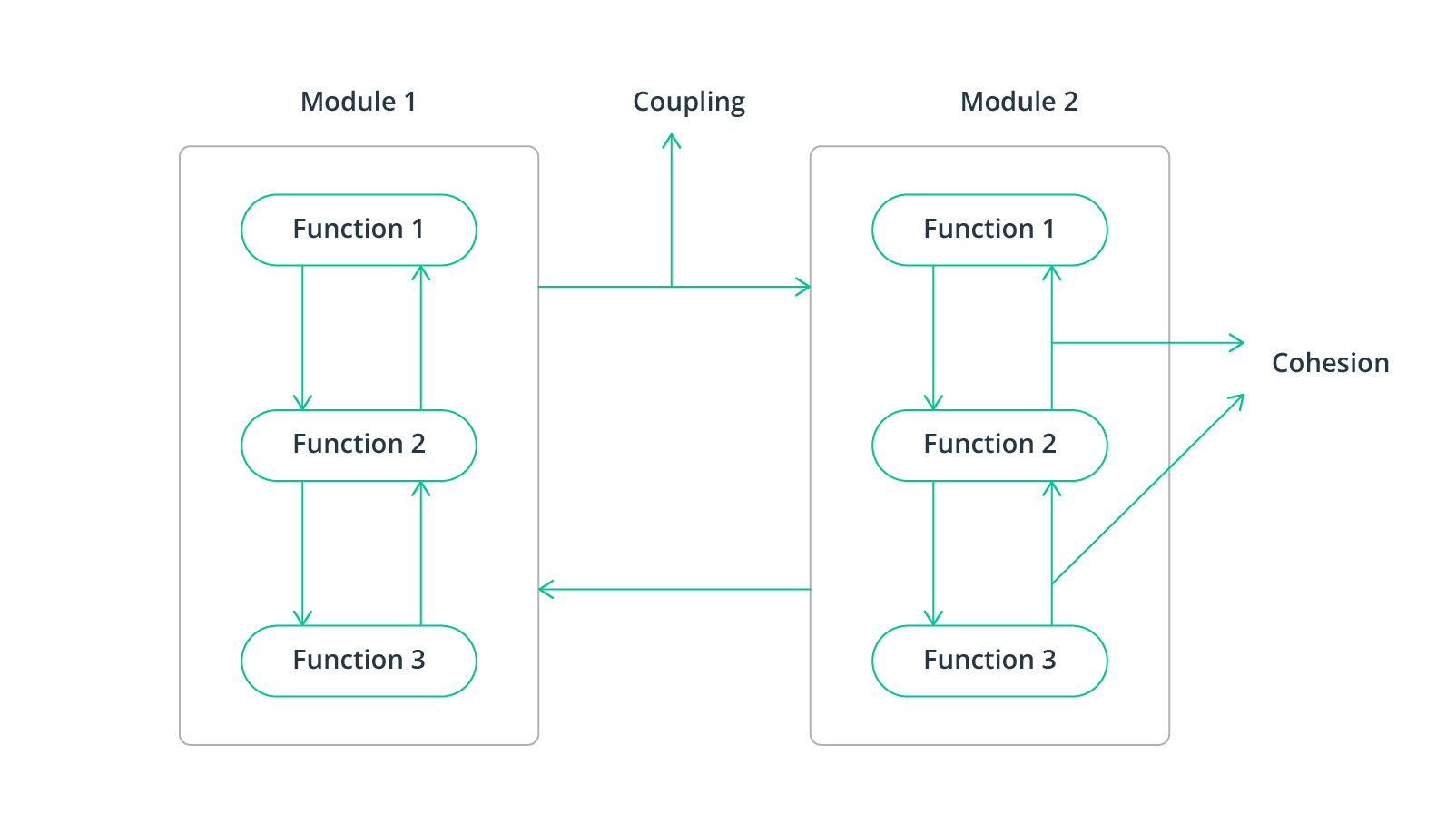
Source: GeeksForGeeks
2. Pipeline automation
The modern practice is to use AI to get rid of most routine tasks in data engineering. Automating data pipelines increases productivity and ensures consistency in data processing. Automated pipelines handle data extraction, transformation, and loading without manual intervention, saving time and reducing errors. Use tools like Apache Airflow or Prefect to set up reliable and efficient automated pipelines.

Source: Estuary.dev
3. Maintain repeatability
You can speed up data processing and improve development productivity by creating reusable solutions for common issues. Design data patterns that address repetitive issues efficiently instead of starting from scratch every time. First identify repeatable issues, then build standard processes to handle them effectively.
Source: Upsolver
4. Security policy for database management
Implement robust security policies to protect data from potential threats. This means tracking all data-related actions and setting rules for secure data access. Categorize data sensitivity issues and define solutions to mitigate risks, then create comprehensive documentation to codify data safety practices and guide new team members. If your organization ever undergoes a security or compliance audit, good security documentation will be critical to passing it.
Source: Venture in Security
5. Maintain proper documentation
Documentation isn’t just for security. Keep detailed records of all aspects of data management, from sourcing to processing. Proper documentation helps everyone on the project understand the data pipelines and security policies inside and out. This practice prevents misunderstandings, ensures continuity, and facilitates onboarding for new team members.
6. Apply DataOps
DataOps is a collection of data practices designed to promote collaboration and efficiency in data analysis. It deals with the entire data lifecycle, from data gathering to successful analysis. DataOps combines different tools and methods to analyze data well. It is increasingly being adopted as a cloud data engineering best practice.

Intellias provides DataOps services that help companies achieve transparency and structure in their data flows. Your data analytics will take on a new life with our team’s expertise.
The Intellias experience
Intellias is a global technology partner with expertise in designing data engineering strategies. We craft scalable end-to-end data processing solutions that give our clients the ability to extract meaningful insights from diverse data sources, regardless of size or complexity. We routinely help companies consolidate data silos and build future-ready platforms. These strategic data engineering solutions enable data-driven decision-making that accelerates market insights, enhances competitive advantage, and drives revenue growth.
Explore data engineering examples from a few of our customer case studies:
Data strategy guidance for a global construction brand.
- A construction industry client engaged us to streamline and optimize their data governance using Azure and Power BI. This project is ongoing, with continuous support to enhance data alignment and transparency for the brand.
Digital retail consulting to orchestrate data flows and operations.
- A global food retailer turned to us for consulting services and improvents to the company’s data platform. This project resulted in a long-term partnership, and many other projects have emerged from it.
A platform for equipment monitoring in supply chains.
- A supermarket chain partnered with us when they needed a real-time big data analytics and temperature monitoring platform for a network of 125 stores in the Baltic States. This reduced energy consumption by 20% and saved the company millions of dollars.
Conclusion
Data engineering is helping businesses make data-driven decisions, provide better services, and react to market demands on time. It’s a vital element of any modern business. Use the data engineering best practices above to get maximum value from your data and reduce costs.
When you need extra assistance, Intellias is your reliable partner in all data-related activities. Our large talent pool of expert engineers will help you create the right data engineering strategy for your organization to extract insights that support your company’s growth. Contact our team today to get a consultation and launch your project.

