DevOps Market size was valued at USD 7.01 Billion in 2021 and is projected to reach USD 51.18 Billion by 2030, growing at a CAGR of 24.7% from 2023 to 2030.
A concept that came into being in 2014, DataOps has already become an integral part of technology implementation by the leaders who are open to the idea of making real-time, relevant data fuel their day-to-day decisions and drive operational efficiency to a new level. The following are the benefits they expect from investing in advanced analytics:
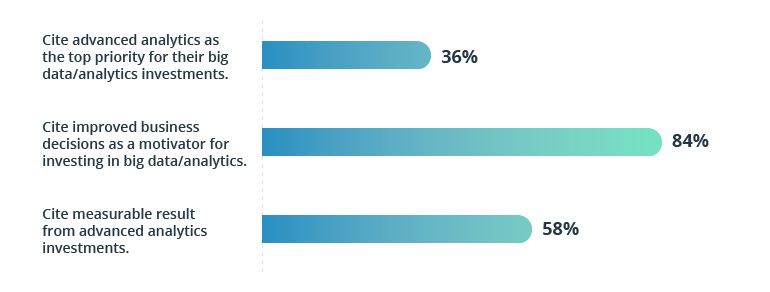
Source: Business Wire
Now that data operations are increasingly playing a leading role within the framework of digital transformation and building of data-driven business models, it is important to recognize the importance of DataOps as an overarching approach to handling data inside organizations and executing long-term data science and big data strategies.
As experts in DevOps, we have expanded into DataOps to provide our clients with a more efficient way to manage their data. For example, Intellias recently helped a European FinTech business cut costs by 20% by implementing the right data strategy and deploying a custom data management solution.
Based on our experience, we’ll explain everything you need to know about how to implement DataOps in your organization and what business challenges this step can solve.
The difference between DataOps and DevOps
Let’s start with definitions. As IBM puts it, “DataOps (data operations) refers to practices that bring speed and agility to end-to-end data pipelines process, from collection to delivery.” There are many other definitions, but the general consensus is that DataOps is, well, DevOps for data, and the difference between DevOps and DataOps is very slight. In fact, they have a lot of shared goals and characteristics:
- Both rely on Big Data and the corresponding cloud infrastructure.
- Both use advanced process automation for testing, data orchestration, deployment, and continuous monitoring.
- Both lean on continuous integration (CI) and continuous deployment/delivery (CD).
- Both aim to curtail the duration of release cycles for software products and valuable datasets by following key Agile principles.
However, DataOps and DevOps differ in the following aspects:
| DevOps | DataOps | |
|---|---|---|
| Focus | Software development | Data quality |
| Roles defined for | Development team | Data users |
| Automated process | Software delivery | Data delivery |
| Optimization | Feedback-oriented | Result-oriented |
DataOps vs DevOps: what is their approach to process optimization?
DevOps encourages stakeholders to provide feedback after every sprint, which the development team uses to optimize software performance and functionality. Meanwhile, DataOps encourages stakeholders to derive new insights from data and feed them back into the system, keeping data fresh and updated without direct intervention from the data management team. Thus, DataOps is an evolution of DevOps practices, advancing the automation of the feedback cycle.
DevOps once revolutionized the way companies were managing their software development workflows through continuous integration and continuous delivery (CI/CD). Internal DevOps services also helped businesses make a smooth transition to cloud computing and achieve new levels of operational efficiency. DataOps promises to do the same for data operations.
Data science and big data projects rely on an uninterrupted flow of data and its round-the-clock availability for end users and AI/ML algorithms. This is where DataOps ties it all together by cultivating a culture based on target-orientedness, flexibility, self-organization, and continuous improvement.
The primary purpose of DevOps is the quick and seamless delivery of fully tested software to business users in 24/7 mode. In a similar fashion, DataOps aims to deliver up-to-date, relevant, and ready-to-use data to each business shareholder within an organization. A properly implemented DataOps framework helps close the gap between all data users: data analysts and scientists, managers, and other big data beneficiaries.
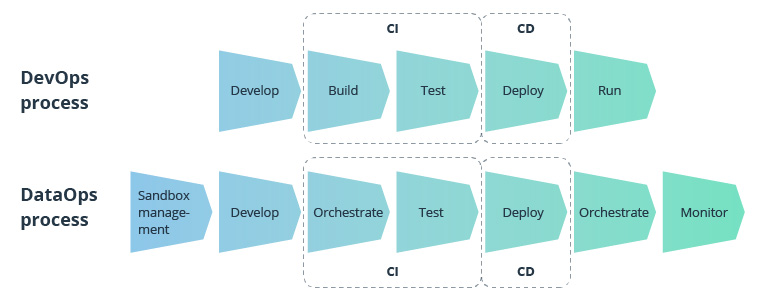
Source: Medium
Making valuable business data accessible to pretty much everyone within an organization has a profoundly positive impact. The most notable advantage is the substantially reduced time of reaction to changes, which is of paramount importance for modern business decision-making. Being able to apply modern data analysis technologies and track frequent changes in vast amounts of big data in near–real-time mode makes the entire company more agile and effective.
At the same time, this approach highlights yet another difference between DevOps and DataOps — the latter often requires the adoption of a new managerial mindset, or even the transformation of the entire corporate culture, to ensure that no insights and opportunities are wasted or overlooked. After all, what difference would it make if a game-changing ML-based prediction is not promptly submitted to a corresponding executive and is only attended to when it’s way too late?
Now that we’ve learned about the importance of DataOps, it’s time to ask: what is DataOps in terms of its transformative power?
Advantages of implementing DataOps
Although DataOps is often mentioned in the context of machine learning and other promising big data trends, it’s not necessarily limited to these areas. It’s a great fit for nearly all data-related activities thanks to the wide gamut of its potential applications and the multiplied benefits it provides to companies working with their data in the cloud and using microservices for their data pipelines.
The most important thing, as mentioned, is that DataOps implementation is not only and not as much about making infrastructural changes and using new tools. In many cases, it’s a lot more about creating new processes and rethinking the way things are currently being done.
Ask yourself the question, “What is ‘data operations’ for my company?” Chances are that your organization may be working with data very selectively, keeping both data and data specialists siloed and isolated from the rest of the company. Occasionally, your data analysts will produce reports and projections intended for particular teams or individuals, but for the most part, no one will really know what’s going on “behind the scenes”.
DataOps is going to change this for good. Isolated teams lack the flexibility and swiftness that are must-haves for companies undergoing digital transformation, so they become natural bottlenecks and a drag on their company’s performance. To achieve greater performance, the DataOps framework suggests the following:
- Bridging the gap between production units and business users
- Making data updates as frequent as possible
- Making data easily accessible to all relevant parties
- Creating cross-functional workgroups augmented with data engineers and scientists who ensure that data governance and orchestration tools are embedded at every step (design, development, and testing)
The last point in the list above may well be the most important one. Tight collaboration between data professionals and software engineers guarantees that both sides get heard and that both functional and non-functional business requirements are observed with maximum efficiency.
DataOps on AWS
As deep and contradictory as the modern concept of data is, for business it is all about quick decision intelligence and value extraction with minimum security concerns. DataOps methodology focuses specifically on bridging data management within key business goals, just what any organization wants. Implementing a DataOps framework means breaking down silos that exist between data and the business using it with efficiency and productivity as the cornerstones of managing the goals.
AWS (Amazon Web Services), being the frontrunner of technology for business world, offers a comprehensive and user-friendly computing platform with the best-fitting tools and data integration services to support cloud DataOps services, including data integration and transformation, storage, security, and analytics.
With the right technology enabler, the AWS services presuppose your pipelines and data platforms are designed, built, and implemented flawlessly across your entire organization according to the standards that help your business scale. This includes IaC (infrastructure as code), CI/CD, user onboarding, AWS cloud security & governance, operational monitoring, and reporting.
By leveraging the benefits of AWS Glue, Amazon S3, Amazon EMR, AWS Step Functions, and Amazon Redshift services, AWS DataOps provides a scalable and secure platform enabling businesses to make insight-driven decisions. From enhancing operational efficiencies to focused analytics and locating new market opportunities to amplifying business outcomes and effective customer experience – AWS platform offers the right DataOps framework to be employed for real-life applications.
Are you looking for new sources of income? You can use AWS Marketplace Insights to identify promising market opportunities and integrate this data into your DataOps system. Similarly, you can leverage the AWS Well-Architected Framework to enhance operational efficiencies.
AWS DataOps Services and expert implementation of the best practices allow to operationalize data management on AWS, implement contemporary data architectures on AWS, build data workflows, accelerate time-to-value for your analytics, and incorporate operational excellence making use of AWS data storage and processing.
Now that we’ve discussed the importance of a good DataOps framework, let’s take a closer look at what makes a framework effective and how its components work together.
Main components of a DataOps framework
An efficient DataOps framework consists of four main elements: data orchestration, governance, CI/CD, and data monitoring and observability.
Data orchestration
Data orchestration ensures that data is efficiently moved and processed throughout the pipeline. This standard is achieved by automating routine tasks, primarily data extraction, transformation, and loading (ETL). Implementing automated ETL between parts of the data management system streamlines the workflow, reduces the risk of clerical errors, and frees your team for more value-adding activities.
Another critical aspect of data orchestration is managing dependencies. Data changes or updates at any processing stage should be immediately reflected throughout the data management system to avoid gaps. This is particularly important for big data operations and DevOps.
Data governance
Data governance ensures the accuracy, consistency, and security of all data stored and used within the organization. This component of a DataOps framework requires the establishment of organization-wide policies, procedures, and standards.
Data governance focuses on data quality, security, and privacy. Common tactics to ensure data quality include validation, cleansing, and adherence to standards. As a result, decision-makers have access to more accurate and complete information, leading to efficiency gains.
The security and privacy aspect of data governance involves techniques such as encryption and access rights management. These techniques protect sensitive data from unauthorized access while making it readily available to authorized users, thereby enhancing organization-wide data security with DataOps implementation.
CI/CD
Similar to DevOps, DataOps requires continuous integration and continuous deployment (CI/CD), including version control and automated testing.
Version control enables data teams to merge changes without conflicts. By seeing each other’s changes in real-time, teams can accept or reject them as needed. Additionally, version control simplifies the process of identifying and rolling back changes that cause errors.
Automated testing—including unit tests, integration tests, and end-to-end tests—should be consistently applied across the data pipeline. This allows data teams to identify and fix issues early on.
Data monitoring and observability
Data monitoring and observability are vital for organizations implementing DataOps. By continuously collecting and analyzing data metrics, data teams can ensure robust workflow performance and detect issues at an early stage.
Another key component of this DataOps framework is data pipeline auditing. As data assets move through the pipeline, changes should be tracked and analyzed in real-time. Data pipeline auditing helps organizations identify suspicious data usage patterns that might indicate security risks or data corruption.
In the process of DataOps integration with the existing data management systems, it is essential to deploy all DataOps components simultaneously as they’re closely interconnected. So, how to implement DataOps so that it benefits your organization?
Planning for DataOps implementation
Now that we’ve answered the question “What is DataOps?”, it’s time we covered some DataOps implementation tips. The good news is that you may not need to start with a clean slate. If a company is considering adding data integration in DevOps to its arsenal, it may already have one of the key items — a DevOps team. From this point, you must follow the three-line DataOps recipe:
1. People
2. Processes
3. Technologies
The vital “zero step” is to assess your current data management systems and processes. Knowing how data is obtained, stored, and used in your organization, you can identify any inefficiencies and bottlenecks and go for the best DataOps framework to fix these.
1. People
If you already have a DevOps team, add a data engineer for building data pipelines and top this off with a data scientist who will put the collected data to good use by building ML models and extracting value from them. Also, consider adding a business analyst to create a collaborative, cross-functional approach within your first DataOps team.
Next, establish a data governance structure that outlines the roles and responsibilities for managing and utilizing data.
2. Processes
We already mentioned that adopting DevOps requires a substantial transformation of the existing paradigm of data governance and cross-departmental cooperation, all for the sake of getting aligned towards a common goal.
On the process side, the following actions may be required to ensure a steady flow of data from multiple sources through teams and internal services to designated destinations:
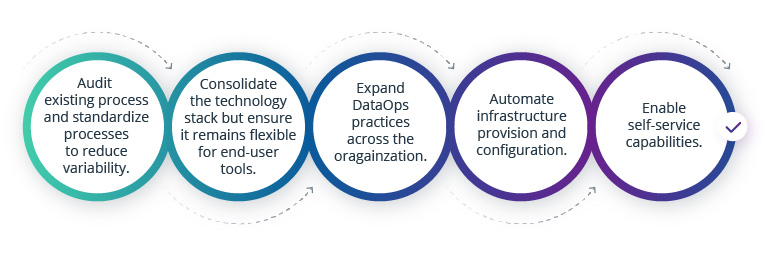
Source: MIT Technology Review Insights
3. Technologies
Finally, from the technology perspective, deep automation appears to be the greatest contributor to the success of DataOps implementation. It ensures that the most data-intensive AI/ML/DL services technologies get enough data or the right quality at the right time, maxing out the accuracy of data analysis and rewarding the company with an up-to-date set of business insights.
Other elements of a fully functional DataOps infrastructure may include the following:
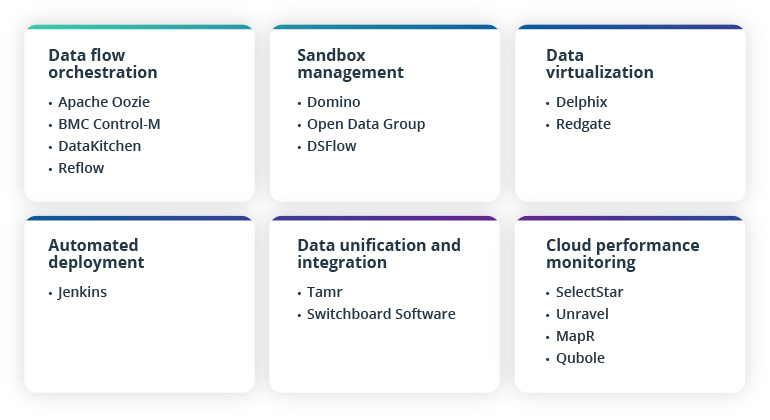
Achieve business agility with DataOps
To implement a DataOps framework, you’ll need to audit your existing data management systems, create a roadmap, and assemble a DataOps team. At Intellias, we offer comprehensive data engineering services and turnkey DataOps deployment. By partnering with us, you can expect:
- A meticulous assessment of your current data management systems
- A tailored DataOps framework designed to address your unique data management challenges
- Efficient implementation of the framework
- Ongoing support to ensure continuous enhancement of your DataOps system
Contact us to give your business a competitive edge with DataOps.

