
Interruptions to business processes can have major consequences, affecting all aspects of business operations and causing severe losses, both financial and reputational. The more sophisticated technology becomes, the more effort it requires to maintain continuous productivity and reliable performance.
For enterprises, downtime often translates into financial losses. According to a survey by Information Technology Intelligence Consulting, for 44% of midsize businesses and large enterprises, just one hour of downtime can cost more than one million dollars.
IT downtime has many causes, from natural disasters destroying physical equipment to human error and cyberattacks. To prevent or at least mitigate the consequences of IT outages, businesses invest billions in disaster recovery (DR) measures. IBM calculated that in 2023, global spending on cybersecurity alone amounted to US$219 billion.
Recognizing the importance of disaster recovery measures, the business community is setting its sights on cloud technologies. Compared to traditional DR strategies, cloud-based solutions offer far more reliable protection against most threats. In this post, we get into the details of disaster recovery in the cloud and outline a basic approach to building an effective cloud disaster recovery plan.
What is disaster recovery in the cloud?
Any DR strategy boils down to setting up redundant resources to back up critical data and applications, enabling their restoration in the event of a disaster. Traditional DR plans involve physical data centers and storage capacities replicating data to protect it and enable access to it to ensure business continuity.
Conceptually, cloud disaster recovery serves the same purpose of replicating and backing up important data to ensure its availability in the event of a disaster. The main difference is that with cloud DR, there are no physical servers directly involved in data replication. Instead, mission-critical data is stored either in a public cloud or on a dedicated provider’s cloud platform.
Increasing adoption of cloud technologies and their use for storing data as a disaster recovery measure has led to the emergence of a dedicated area of cloud computing, disaster recovery as a service (DRaaS), in which cloud providers host business infrastructure. DRaaS keeps gaining traction and, according to Markets and Markets, is expected to reach a market value of US$26.5 billion globally by 2028.
Disaster recovery as service global market forecast (USD Bn)
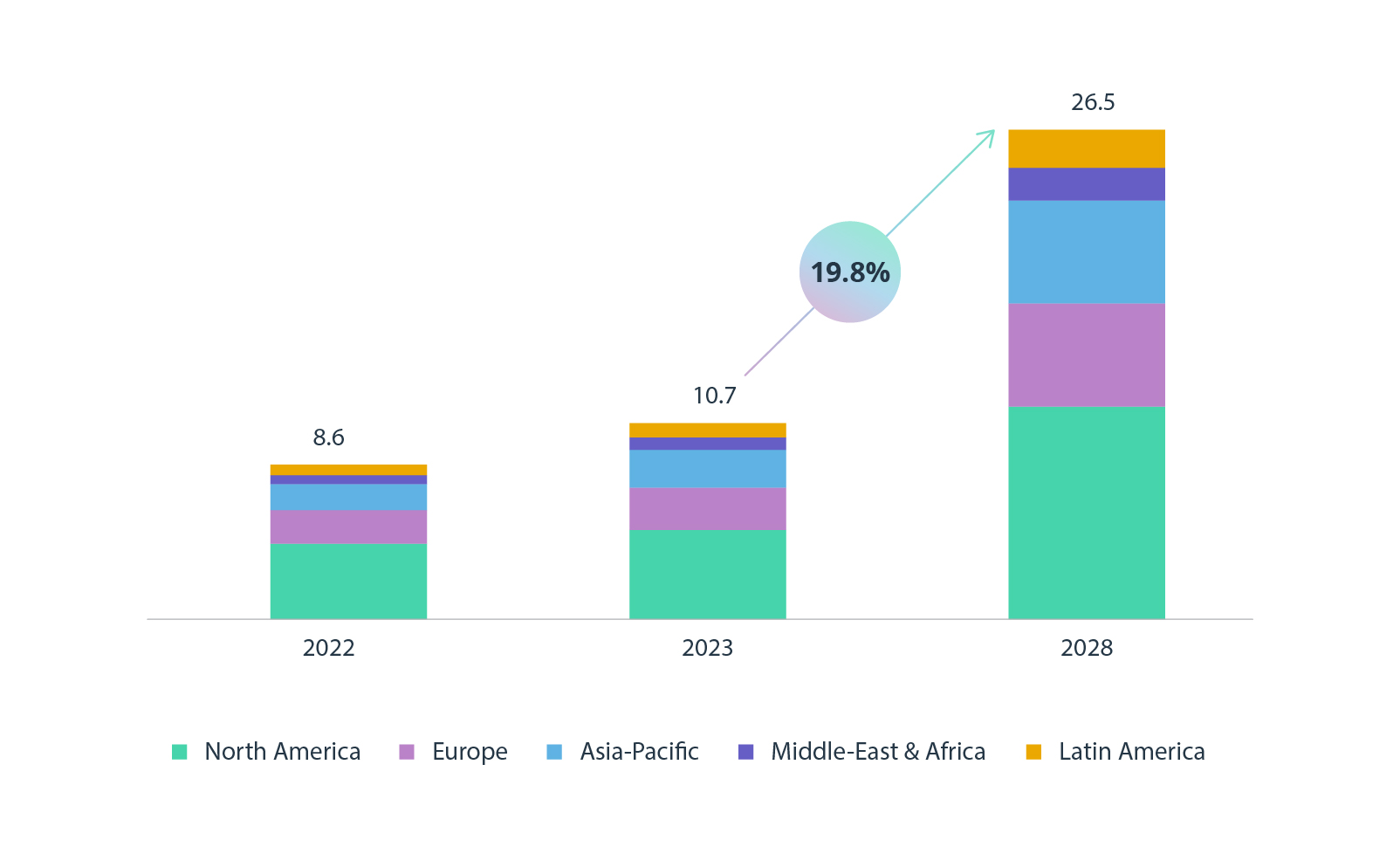
Source
Cloud disaster recovery vs. traditional disaster recovery
Whether to invest in disaster recovery is no longer a question: an increasing number of business processes depend on information technology. Instead, businesses have to decide whether to opt for traditional on-premises backup infrastructure or for cloud solutions.
Both approaches have their pros and cons that need to be weighed carefully when choosing the DR strategy for your business. Your choice between an on-premises setup and cloud disaster recovery as a service should take into account both the benefits you expect to receive and your organization’s limitations, such as your budget, business flows, and available workforce and skills.
Let’s compare the main factors that may influence your choice.
| On-premises | Cloud | |
|---|---|---|
| Ease of launch | DR configuration requires setting up redundant physical infrastructure, which needs to be done by technical IT staff. | In-house IT staff only needs to configure connectivity to the cloud provider, while the actual setup is done on the provider’s side. |
| Customization | Physical infrastructure may be selected according to specific business requirements; however, subsequent changes may be difficult and expensive. | While there may be certain limitations resulting from the provider’s capacities, cloud solutions offer flexibility both in the selection of available options and infrastructure updates. |
| Infrastructure costs | There are high upfront costs, including equipment and the space to host it. Ongoing costs may be high, too, covering power, cooling, and equipment maintenance. | DRaaS involves an affordable initial investment while providing a full range of cloud backup and disaster recovery services. Most cloud providers offer flexible pay-as-you-go pricing models, allowing you to pay only for what you consume. |
| Scalability | Scalability is limited to the capacity of physical equipment. Scaling requires additional investments in hardware and its installation. | Cloud solutions easily scale up and down based on the actual workload and business growth. You only pay for the cloud computing resources you use in your DR activities. |
| Reliability | Local DR infrastructure has the same vulnerabilities as the primary infrastructure. Physical servers can be affected by network outages, power failures, or cyberattacks. | With geographically distributed coverage, cloud networks provide consistent service and have better failover options. |
| Uptime and data recovery | Physical infrastructure may have slower data recovery, resulting in more unpredictable downtime. | With always-on replication used in DRaaS solutions, data recovery is significantly faster. |
| Latency | The proximity of on-site servers may reduce the latency of the DR infrastructure. | Cloud DR solutions may have latency issues caused by the geographic location of the particular cloud server. |
| Control | With DR resources in your direct ownership, you may have stronger control over the infrastructure. | The cloud provider primarily controls the infrastructure, increasing the level of dependency on their operation. |
| Maintenance | Both routine maintenance and emergency response require qualified IT staff to be present to ensure business continuity. | Regular maintenance and emergency response are the responsibility of the cloud provider. Moreover, the cloud services provider has more opportunities to implement automation and self-healing practices to secure consistent operations than its users. |
Creating a cloud-based disaster recovery plan
In designing your cloud DR strategy and plan, assume that incidents will inevitably happen. The point is to prevent or minimize their effect on your business and secure the service-level agreements (SLAs) you have committed to. A successful DR plan should provide a reliable method for quickly recovering your data and restoring business continuity.
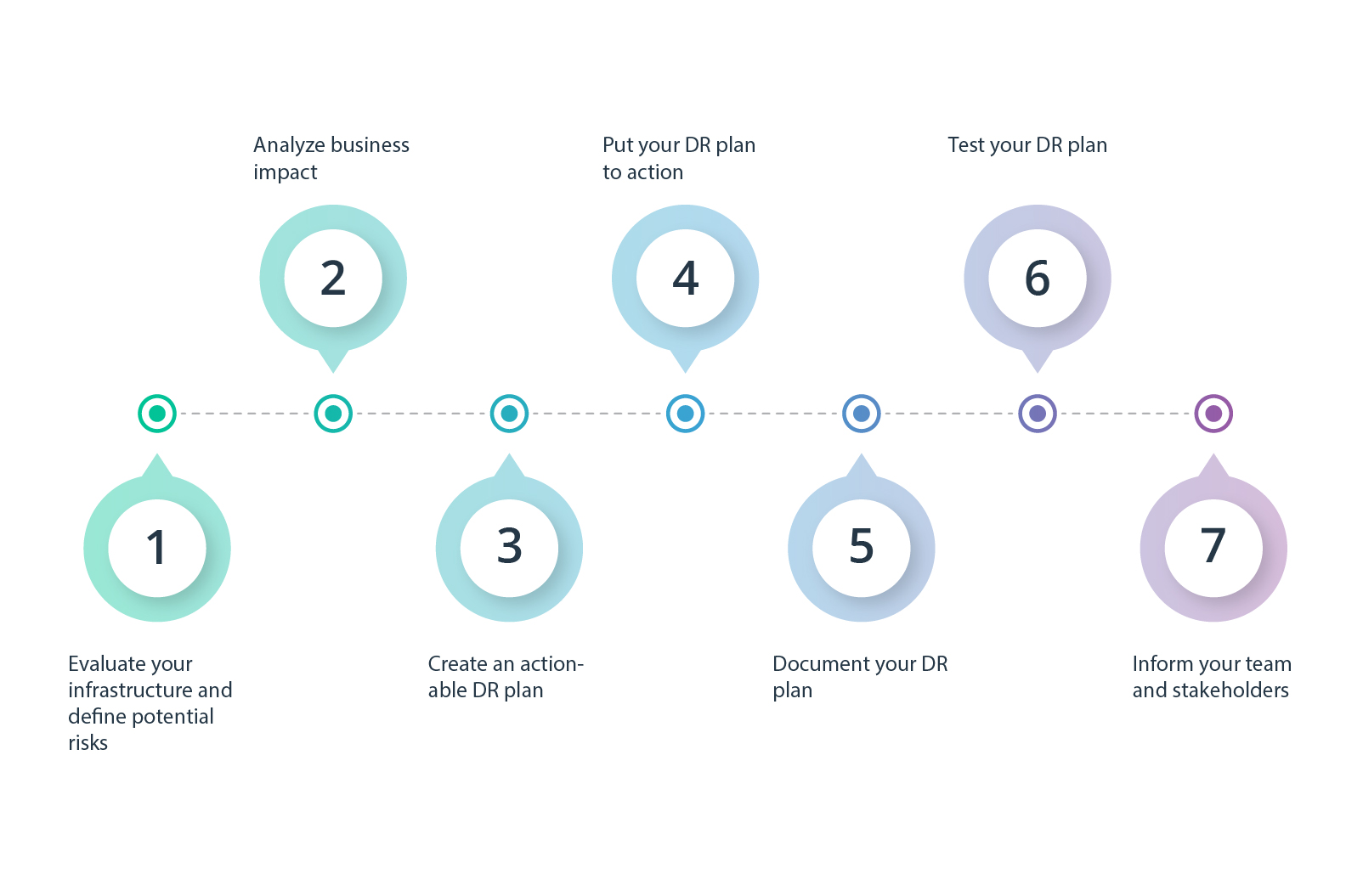
Let’s walk through the steps of designing a working DR plan. Note, however, that a cloud-based disaster recovery approach requires certain special IT knowledge and experience of working with cloud technologies. While the bulk of the DR infrastructure is set up by the cloud provider, local IT engineers should configure the necessary connectivity.
1. Evaluate your infrastructure and define potential risks
Start planning your disaster recovery by conducting an inventory of your assets and data that need to be protected from failures and attacks. Knowing what you have, where everything is stored, and how critical each piece of data is will help you set priorities in designing recovery solutions for your infrastructure.
At the same time, estimate potential risks to your assets. Include all possible natural and human-induced incidents, such as natural disasters, power failures, data breaches, and other cyberattacks in your research. Knowing the risks helps you visualize possible redundancy and replication methods that can secure a quick recovery.
2. Analyze business impact
Once you have identified your strategic assets and evaluated the potential risks to them, analyze how disasters could affect your operations and service. Start with reviewing the service-level objectives (SLOs) and service-level agreements (SLAs) you have committed to in your arrangements with clients. Based on these, you can determine reliability targets that will help you design your cloud DR strategy:
- Recovery Time Objective (RTO) is the maximum time your product can stay down after an incident. This parameter defines the time period within which you can restore the service without major consequences for your business. After the RTO expires, the absence of or disruption in service may become unacceptable for clients.RTO varies from business to business, depending on the type of service delivery. Obviously, RTO is at its lowest for companies offering fast delivery, requiring them to take extended recovery measures. For moderate-paced services, RTO may be longer, allowing more time to restore operations.
- Recovery Point Objective (RPO) defines the maximum amount of data you can afford to lose during recovering from a failure. RPO is measured as time elapsed before data is compromised. For time-critical businesses, RPO is extremely short, which forces them to focus on frequent data backups to minimize losses. Businesses that are less time-restricted can perform backups less frequently.
Both RTO and RPO are important in designing a reliable DR strategy, so you should invest time in calculating these numbers and ensure your objectives are realistic and achievable. Also, make sure that you define RTO and RPO for each stage of your workflow.

3. Create an actionable DR plan
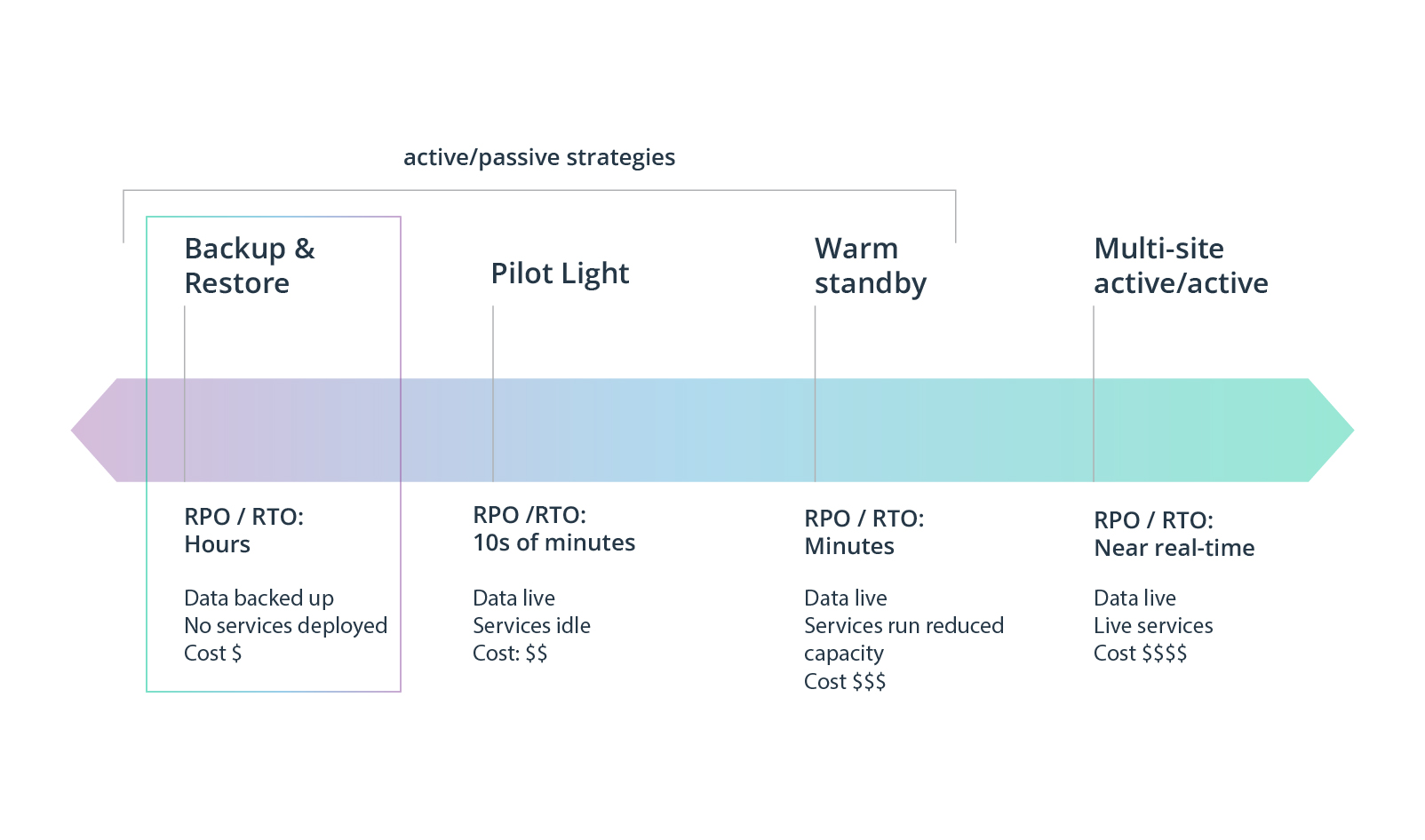
Use your RTO and RPO as the reference for laying down DR patterns you need to implement. These values can help you select a general approach to building your cloud disaster recovery strategy. There are several basic types of cloud DR strategies to choose from:
- Backup and restore. This is the most straightforward approach to disaster recovery, where you store snapshots of your entire volume of data and applications, updating them on a regular basis. In the event of a failure, you can recover your system from the most current backup. This approach is recommended for services with a high RTO and RPO, as it involves the longest downtime.
- Pilot light. This strategy focuses on replicating your application’s core functionality in the cloud. With the pilot light strategy, cloud infrastructure runs alongside the main infrastructure and regularly updates critical data. This allows for recovery of your environment by scaling it up from services running in the cloud. A pilot light strategy is quicker than backup and restore; however, it is also more expensive due to the constantly running cloud infrastructure.
- Warm standby. If you opt for this approach, you will need to duplicate your entire environment in the cloud and keep it running continuously (but under a reduced load). In the event of a failure, such infrastructure can restore the service quickly, as it is already fully deployed and only needs to be scaled. Warm standby may be the preferred DR method for services with short RTOs. At the same time, it may be rather costly due to constant consumption of cloud resources.
- Multi-Site. With multi-site, you create an exact replica of your environment and have it running at full capacity alongside your main environment. This ensures an almost immediate restoration of services in case of a disaster, as there is no need for additional deployment or scaling. While highly effective, the multi-site approach is also expensive, as it requires constantly maintaining two identical infrastructures. Therefore, you should only consider multi-site for the most critical applications that cannot afford even minimal downtime.
4. Put your DR plan to action
Once you have selected the cloud DR approach that meets your business requirements, it’s time to take steps to implement it.
- Find the right cloud provider. The best way to approach the transition to DR in the cloud is to collaborate with a professional provider of cloud services. Companies with expertise in the field of cloud computing and cloud-based DR solutions will consult you on how to implement a disaster recovery plan that meets your requirements.That said, let’s take a brief look at DR offerings by the leaders in the cloud computing services market:
- Azure Site Recovery by Microsoft works with the multi-site approach, replicating your infrastructure in the cloud to ensure quick recovery in the event of failure. Azure Site Recovery supports replication both between on-site infrastructure and cloud infrastructure and between two Azure cloud regions.
- AWS Backup and AWS Elastic Disaster Recovery. AWS offers various cloud DR services you can choose from depending on the disaster recovery method you have selected. You can back up your data, duplicating it in multiple AWS availability zones for maximum security. Alternatively, you can opt for any other method, replicating either all or a critical part of your infrastructure. AWS allows you to back up both on-premises and cloud infrastructure with minimum downtime and at reasonable cost with the pay-as-you-go model.
- Google Cloud Backup and DR Service. With a distributed global network and lots of points of presence, Google Cloud offers sufficient scalability and redundancy to maintain any DR method you choose for your application. You can back up your data regularly using Google Cloud storage or choose a complete replication for immediate recovery.
- Configure your cloud DR infrastructure. After you choose the cloud DR provider, you can set up the DR resources. Proceeding from the DR strategy you have selected and the amount of data and functions you need to back up, plan the following:
- The elements of cloud infrastructure you are going to deploy. Think of the servers, storage capacities, and connections you need to implement to run the DR infrastructure.
- User authentication and authorization. Design the access management system you are going to use for the cloud infrastructure.
- Security and compliance. Review the security requirements and legal regulations applicable to your product and verify that the selected cloud DR infrastructure complies with them.
- Disaster prevention measures. While planning disaster recovery tactics, think about what you can do to prevent disasters or minimize their effect.
5. Document your DR plan
Prepare comprehensive documentation covering all aspects of your disaster recovery plan:
- Definition of the disaster. Describe the events that are considered a disaster and trigger the DR plan.
- Actions taken within the DR plan. Lay down a detailed sequence of actions that will be performed after the DR plan is activated.
- Roles and responsibilities. Assign participants in DR activities and actions each of them must take.
Maintain and update your DR documentation as necessary. It should always reflect the current state of your disaster recovery strategy and contain all the information your team needs to act.
6. Test your DR plan
Once you have all DR steps laid down, test them in your system. With live tests, you will be able to validate the chosen strategy and verify that the plan you have built runs successfully. Such tests can help you identify gaps or steps you may have overlooked in your planning.
Run DR tests regularly to ensure that the plan you have designed can accommodate your growing or changing business. If you make any major updates or revisions to your main infrastructure, make sure to do DR tests to verify that the selected strategy still works. Otherwise, make the necessary adjustments.
7. Inform your team and stakeholders
Present your DR plan to all the stakeholders in your company: technology leaders, business decision-makers, and immediate participants in DR activities. With such updates, everyone will be on the same page, and you will achieve the necessary transparency in regard to the costs and resources required to implement the disaster recovery strategy.
Cloud disaster recovery and business continuity: success stories
Every business that uses data and IT in its operations invests in disaster recovery. Such investments pay back in spades, protecting critical data and services and allowing companies to restore business continuity ASAP.
Let’s see how some well-known brands have set up their disaster recovery strategies.
Salesforce
The company is committed to maintaining business continuity with minimum interruptions to provide services to thousands of customers. For Salesforce, disaster recovery is one of the acceptance criteria whenever any changes are introduced. For each of its services, Salesforce maintains separate documentation summarizing measures the company takes to prevent disruptions.
In general, Salesforce uses a multi-site DR method that it calls Site Switch. Essentially, each Salesforce instance exists in two geographic locations with data synchronized between them in near real time. Whenever maintenance is required or a disaster occurs, the service is switched to the other location.
Netflix
The streaming service chose AWS as their provider of cloud disaster recovery resources. After a major AWS outage in 2012, which interrupted service for many customers across multiple regions – and on Christmas Eve, too! – Netflix strengthened its DR measures, replicating data across several AWS zones. This backup strategy enables the company to quickly switch traffic in the event of a failure, ensuring service continuity for customers.
Moreover, Netflix conducts regular resilience tests using its own tool called Chaos Monkey. The tool turns off some of the equipment in the production network to see how the remaining hardware handles the increased load.
Delta Air Lines
This case could have been a story of failure rather than success. In 2016, Delta Air Lines experienced a massive outage of its IT network, causing the cancellation of thousands of flights and a loss of about $100 million in revenue.
However, the incident could have been even more disastrous if the IT staff of the airline did not implement backup measures that allowed them to restore service within six hours. Thanks to redundant servers and data replication, they managed to recover core services. Still, the case became a lesson of how important it is to have proper backup in place.

The Intellias approach
In our projects, we always pay close attention to disaster recovery, backup, and replication to make sure that our clients’ data is safe and their business is protected from interruptions. Moreover, for some clients, we redesign their systems entirely to ensure reliable disaster recovery and business continuity.
To help clients ensure reliable performance of their infrastructure and verify its ability to recover effectively in the event of failure, we recommend a Well-Architected Review, which represents a complete evaluation of the client’s infrastructure. As part of the Well-Architected Review, we perform a reliability check verifying the system’s ability to withstand loads and identifying deficiencies that may affect its resilience.
Based on our findings, we provide actionable recommendations on the improvements needed to strengthen the business’s fault tolerance, as well as outline an appropriate disaster recovery strategy.
On a final note
Cloud disaster recovery is fundamental for an uninterrupted data flow and downtime reduction, safeguarding against a company’s revenue loss and reputational damage following unexpected disruptions. It also provides scalability and cost-effectiveness, allowing for custom recovery solutions that fit specific needs without hefty upfront infrastructure investments.
Though there is no silver bullet to cover all the causes of potential disruptions, today’s organizations have viable tools and technologies to protect themselves from service interruptions. While the path to reliable disaster recovery in the cloud may be challenging, companies from across every sector don’t have to do it alone; they can always get meaningful assistance from service vendors and industry insiders. From meticulous advisory to legacy systems modernization with cloud adoption to backup provisions and disaster recovery capabilities, Intellias will help you implement solutions to maintain operations and protect your company from the unexpected.

