Automotive engineers keep racking their brains about how to approach autonomous driving. OEMs keep giving multimillion-dollar injections to their R&D departments and partnering with tech companies and Tier 1 providers to increase driving autonomy. Meanwhile, self-driving must not only become reality but win people’s hearts. And the key to winning hearts is providing high intelligence and safety, often with the help of machine learning in self-driving cars.
Can machine learning in autonomous cars help manufacturers? Will self-driving car supervised learning or unsupervised learning algorithms make a difference in driving automation? Let’s find out from our experts.
In this article, you’ll read about:
- Supervised vs unsupervised machine learning methods
- The most popular classes of unsupervised learning
- Which categories of unsupervised learning algorithms are used in driving automation
- Which algorithms fit into the unsupervised ML categories of clustering, simulation, and test data generation
- Benefits of unsupervised learning
- Use cases of machine learning algorithms in automotive
Normally, it takes not just a month or even a year for a human to feel confident behind the wheel. So what can we expect from machines? Machine learning in self-driving cars powers the progress. A lot of learning. And machine learning, in turn, demands data to learn from. Autonomous driving desperately needs both machine learning algorithms and data to train them on. What’s left for us humans is to provide that data while choosing the correct machine learning methods. We’ve already started sorting out why machine learning algorithms are an integral part of autonomous driving. To support this claim, let’s look at unsupervised machine learning, a branch of artificial intelligence (AI) that helps machines learn effectively.
Just in case you forgot what unsupervised learning is…
The term unsupervised learning refers to AI/ML training models and is the opposite of supervised learning. Supervised learning algorithms rely on labeled input data and features of the learning environment. This way, the program predicts output based on data it has classified.
Unsupervised machine learning tries to score more points for artificial intelligence without any human touch. Unsupervised machine learning algorithms rely on data that has no labels, predefined features, or specified classification sets. Unsupervised AI/ML systems learn from the deep-rooted structure of the input data.
Which are the most popular classes of unsupervised learning algorithms and which are used in driving automation?
There are plenty of unsupervised machine learning algorithms and many categories they can belong to. Unsupervised machine learning algorithms can be categorized according to the methods they use to group and process data.
One classification of unsupervised machine learning algorithms
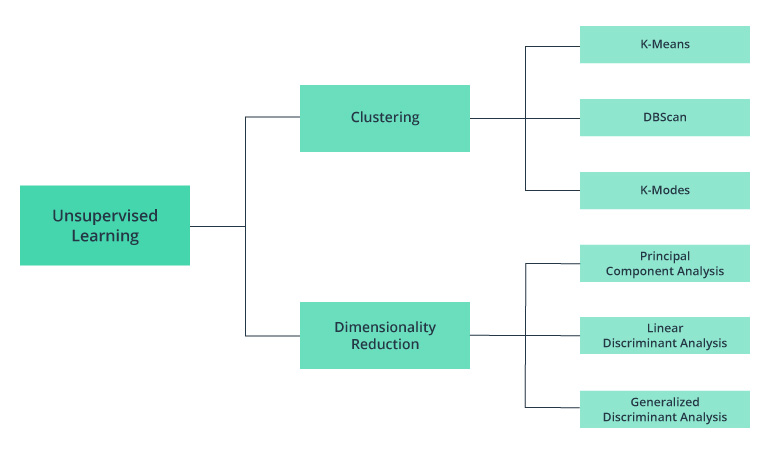
Teradata – TheTree of Machine Learning Algorithms
In applying basic unsupervised learning techniques, data scientists use the following tried-and-true approaches:
- Feature separation techniques
- Principal component analysis (PCA)
- Singular-value decomposition (SVD)
- Expectation-maximization algorithms
- Biclustering
Selecting unsupervised learning models for self-driving car development is the prerogative of an experienced team of data scientists familiar with the pros and cons of each model. Depending on the tasks self-driving engineers are solving, the above-mentioned unsupervised approaches can be used in machine learning in self-driving cars.
Still, having analyzed dozens of use cases from the automotive domain (check out practical use cases in the final section of this article), we can conclude that automakers and their data science teams most commonly use unsupervised learning models in self-driving cars:
- Clustering
- Simulation and test data generation
- Anomaly detection
Clustering
The clustering technique is one of the most effective yet relatively simple unsupervised learning methods to group data points while looking for the inherent structures and features in input data.
When it comes to machine learning in autonomous cars, clustering techniques build data-based prediction and feature selection models for:
- object detection
- driving encounter scenarios
- traffic information detection
- trajectory selection
At some point, self-driving car supervised learning models may fail. In such cases, when data points are limited, data is discontinuous, or systems have only low-resolution, clustering algorithms may be the right solution. For instance, classification algorithms may work incorrectly while detecting road signs from a particular category in unfavorable weather conditions (like fog) or when there are certain obstacles (like a tree). But clustering algorithms may succeed with these tasks thanks to their ability to detect the inherent structure of objects.
Some of the typical clustering unsupervised machine learning algorithms used in automotive are k-means, mean shift clustering, and DBSCAN.
K-means
This algorithm takes data points as an input and groups them into “k” clusters. It assigns each data item to the nearest cluster center. Following the training phase, it returns an output where all data points are known as attributes of particular clusters.
Example of how k-means clustering works
K-means clustering in Python
Among other use cases, data scientists use the k-means algorithm for detecting lane boundaries and converting training data into the appropriate format for further processing in autonomous systems.
Mean shift clustering
This type of unsupervised learning algorithm is widely used and considered an advanced and versatile technique for clustering-based segmentation. Take a look at one definition of mean-shift clustering:
Given a set of data points, the algorithm iteratively assigns each data point towards the closest cluster centroid. The direction to the closest cluster centroid is determined by where most of the points nearby are at. So with each iteration, every data point will move closer to where the most points are at, which is or will lead to the cluster center. When the algorithm stops, each point is assigned to a cluster.
Original unclustered data vs clusters found by mean shift
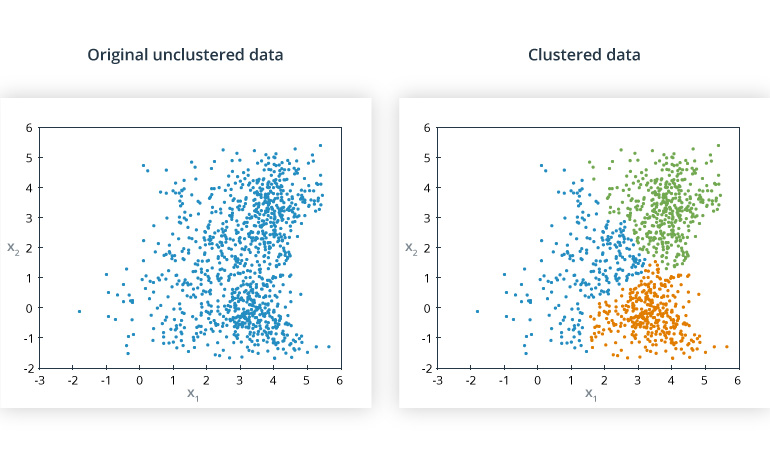
GitHub – Compare Python clustering algorithms
In autonomous driving, mean shift algorithms are used for advanced image processing and computer vision development.
Density-based spatial clustering of applications with noise (DBSCAN)
This method separates clusters of high density from clusters of low density, seeking areas in the data with a high density of observations. It requires a preset minimum number of data points to determine a single cluster, which turns into the output of defined outliers in the dataset.
Original unclustered data vs clustering performed by DBSCAN


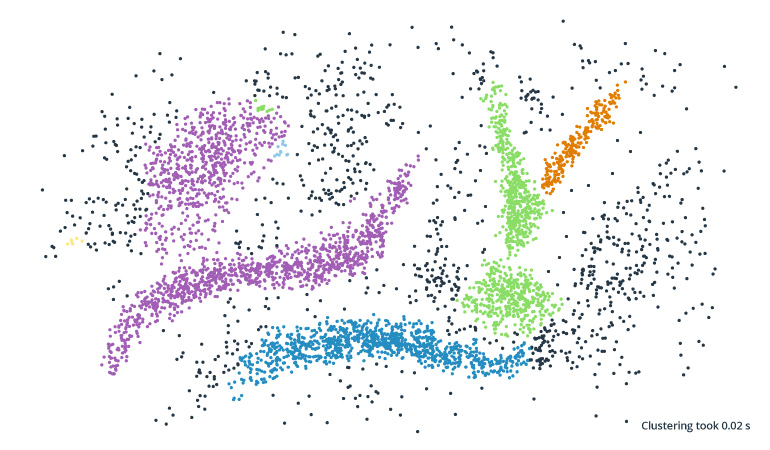
GitHub – Compare Python clustering algorithms
Data scientists use DBSCAN algorithms in autonomous driving for advanced image processing, clustering of driving scenarios, and computer vision development.
Using unsupervised learning for simulation and test data generation
Researchers working on driverless cars using unsupervised learning are constantly looking for ways to automatically generate test cases to mirror real-world driving scenarios. According to some estimates, autonomous vehicles will need to drive billions of miles to demonstrate the desired safety and reliability. But driving billions of miles would take decades and cost a small fortune. That’s why data scientists prefer to generate large amounts of realistic driving scenarios using unsupervised machine learning models. This way, they can test the reliability and safety of simulated autonomous driving systems across different driving conditions and scenarios.
Going the other direction and omitting real-world training, the autonomous vehicle concept meets other challenges. One of them is the need for a mind-blowing amount of training. Huge training datasets must represent examples of all possible driving, weather, and situations to achieve the high level of performance. How can we obtain petabytes of training data without spending decades driving and capturing images? One possible answer is by generating synthetic data. The next question is how self-driving simulations can be properly designed using synthetic data. One rational possibility is by using Generative Adversarial Networks (GANs).
Using GANs in autonomous driving systems
Even though a GAN is called an unsupervised learning method, its logic works with an unsupervised problem as though it were a supervised one. It consists of both generative and discriminative algorithms that are opposed to each other. The generator produces examples, and the discriminator evaluates these examples, trying to classify them as real or fake. “Real” examples are those trained on the actual data from the training dataset. Both generative and discriminative algorithms are trained together until they achieve the maximum level of accuracy.
GAN as a training method
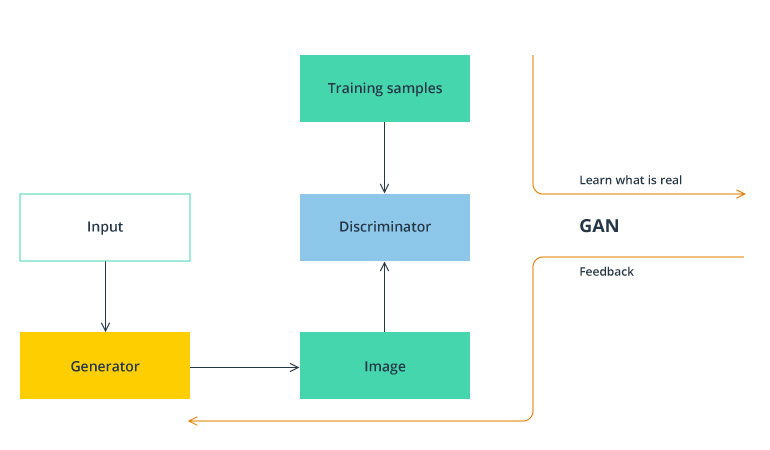
Medium – GAN — What is a Generative Adversarial Network (GAN)?
To train self-driving cars, a GAN helps to provide data from scratch – mostly images, since it can learn to mimic any distribution of data.
Autoencoder in self-driving simulation
Another approach to driving simulation using unsupervised machine learning models is being developed through autoencoders. This type of unsupervised artificial neural network compresses and encodes raw data input and then tries to reconstruct the output based on the compressed or hidden data representation.
Autoencoding algorithms in action
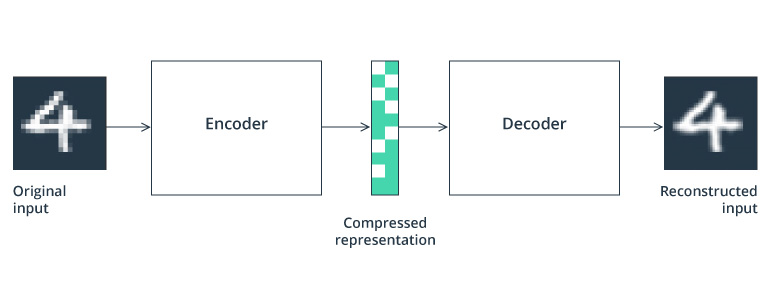
The Keras Blog – Building autoencoders in Keras
In autonomous driving models, autoencoders are widely used for simulating driving behavior and predicting risk patterns. Being fed by data from sensors and cameras, autoencoders help to create a realistic testing environment to train vehicles on object avoidance, reactionary control, lane following, and even vehicle steering.
Anomaly detection algorithms used in autonomous vehicles
Safety concerns and lack of trust are still among the top reasons people would refuse to ride in an autonomous vehicle. Unsupervised machine learning in a self-driving car can prevent fatal crashes and disruptive consequences. Anomaly detection methods can be one of the cures.
Security systems in end-to-end learning for self-driving cars should be equipped with anomaly detection modules, which do not focus on recognizing threats first. Instead, they first try to recognize abnormal behaviors of the autonomous vehicle, thereby preventing severe security implications. When unusual behavior is detected, the system looks for the cause of the anomaly and tries to remove it. On top of behavioral analysis, anomaly detection methods support Intrusion Detection Systems (IDS) and malware protection.
An autonomous vehicle that has never encountered an elephant, for example, would classify it as an object with unpredictable behavior and would stop the car or switch to human control. At the same time, driving on the left side of the road in Singapore might differ from the training scenarios but wouldn’t be considered anomalous.
Local Outlier Factor (LOF)
One of the unsupervised learning methods of anomaly detection used in autonomous driving is Local Outlier Factor (LOF). A commonly used tool, LOF represents a score that tells how likely it is that a certain data point is an outlier/anomaly. A LOF method computes the local density deviation of data points within a particular data set compared to their neighbors.
Unsupervised learning vs supervised: Where are the solutions to automation issues?
Autonomous vehicles are such complex data centers – composed of various operating systems, control units, and components – that there are enough tasks for all sorts of machine learning algorithms. Supervised learning and unsupervised learning have their pros and cons depending on the use case. Still, many people believe it will be unsupervised rather than supervised learning that will allow us to approach the fifth level of automation. Here are some reasons why:
- Better scalability. The majority of unsupervised machine learning algorithms require no manual labeling of monitored signals. This means better scalability with extensive datasets.
- Less expensive. In terms of data labeling, unsupervised machine learning is more economical, as labeling data is quite expensive and time-consuming.
- Less time and effort required to collect data. With synthetic data, scientists can reduce the amount of real-world training data needed. Real-world data is hard to acquire but is required to develop high-quality computer vision models.
- Better performance and lower hardware requirements. Unsupervised learning models in self-driving cars can automatically learn road features with minimal input from a human driver. Neural networks, for instance, need a minimum of training data to choose from the available commands, such as move forward, left, right, and stop.
- Bias-free. Although this point is a bit controversial, it’s a fact that bias variance is among the main drawbacks of supervised learning models. With less human input, unsupervised machine learning algorithms are supposed to be more bias-resistant.
Big market players are ready to invest in machine learning and unsupervised learning models in self-driving cars
The biggest challenge the global automotive community of data scientists faces is making end-to-end learning for self-driving cars, that means supervised and unsupervised machine learning algorithms, applicable to a wider variety of deployment scenarios. Nowadays, among other applications, machine learning algorithms are widely used by OEMs and Tier 1 providers to evaluate the driver’s health, classify driving scenarios, and assist in manufacturing. At the same time, machine learning remains an attractive field for automotive and one of the preconditions for self-driving cars. These are just some of the things businesses are using machine learning algorithms for:
- Enhancing the accuracy of AV performance. Cortica, an Israel-based company, together with Renesas Electronics, uses unsupervised learning models embedded in the Renesas R-Car V3H system-on-a-chip for their self-driving car concept. They state that their unsupervised learning algorithms can now make predictions based on the visual data received from forward-facing cameras. This way, the company plans to increase the system’s ability to react to any situation, whether or not objects or circumstances were previously converted to rules by deep learning.
- Simulating the worst driving scenarios. Waymo’s self-driving system relies heavily on machine learning algorithms, including neural networks. The company has designed a neural network to copy human driving, especially in the worst scenarios. The ultimate goal, of course, is preventing fatal consequences in level five automation.
- Predicting failures and required service. Volvo uses machine learning algorithms to analyze massive sets of accumulated data, paying special attention to preventing breakdowns and failures.
- Teaching how to drive safely with synthetic data. Google’s self-driving cars rack up 3 million simulated miles every day. This way, Google not only increases driving safety but uses simulations to create new scenarios based on real-world situations.
- Building self-driving concepts for public roads. The UK company Wayve has successfully tested their imitation learning and reinforcement learning algorithms for self-driving cars on public roads in the UK, with no driving rules being hand-coded. Their autonomous platform was built and tested on the fully electric Jaguar I-PACE SUV.
Despite all the challenges and concerns, 55% of Americans believe that by 2029, most cars will be able to drive themselves. We believe that improvements in deep learning for self-driving cars, AI and machine learning algorithms – whether the result of supervised or unsupervised learning models – will definitely contribute to the successful future of autonomous driving.
Contact our automotive experts at Intellias to discover more about the practical applications of deep learning for self-driving cars and unsupervised learning algorithms in autonomous vehicles.


