But for many enterprises, the big question isn’t whether to use generative AI — it’s how to use it without giving up control.
If your team handles sensitive financials, proprietary customer data, or competitive intel, sending prompts to a public model isn’t ideal. That’s where running a local LLM comes in. It’s one way organizations are using GenAI on their own terms, with more privacy, faster performance, and tighter integration.
In this guide, we’ll show you how to run LLMs locally, walk through real enterprise use cases, and break down the tools and trade-offs of deploying local AI models for businesses. Whether you’re just exploring or planning a full rollout, you’ll get a clear view of how enterprise local LLMs can (or can’t) fit into your stack.
Why enterprises are running LLMs locally
Every time you prompt a cloud-based model like ChatGPT, your data leaves the building. The more detailed the prompt, the better the output, but you’re also sharing more information with a third party.
For teams working with sensitive information, that’s a non-starter. That’s why some enterprises are exploring running local LLMs, keeping models on their own infrastructure, so data stays private, secure, and in their control.
But privacy isn’t the only reason local LLMs are getting attention:
- Sharper answers: General-purpose models like ChatGPT or Gemini know a little about it. But they don’t know you. A local LLM, fine-tuned on internal data, can speak your language, understand your metrics, and deliver more relevant results.
- Faster performance: When you run an LLM locally, there’s no internet hop. That means low latency and instant responses, which are ideal for real-time use cases like translation tools, voice assistants, or internal chatbots.
- Built-in resilience: Local models don’t go down when your API provider does. They run offline, right on your hardware, with no external dependencies.
Enterprise use cases for running a local LLM
Anywhere you’ve got unstructured information — long docs, scattered tickets, overflowing inboxes — there’s a good chance GenAI can help. And for some teams, running a local LLM makes that help a lot more practical.
Here are a few places where enterprise local LLMs are already making a real impact.
Chatbots for customer support
Capgemini found that 63% of retailers use Gen AI in their customer support chatbots. And it’s not just retailers. Salesforce uses its Einstein models to cut response times in half.
But offloading customer data to a public LLM? That’s a risky move. That’s why some companies are training local LLMs on internal knowledge bases, ticket histories, and FAQs and running them directly inside their support tools. You get faster answers, reduced agent load, and complete control over sensitive data.
Developer productivity
Generative AI is helping developers make massive leaps in productivity. Research shows LLM-assisted devs are up to 55% more productive, especially when writing boilerplate code, debugging, or generating tests.
We’ve seen this firsthand. We’ve built local chatbots for GitHub and VS Code to surface documentation, explain legacy code, and suggest improvements without sending a single line outside our firewall. It’s fast, accurate, and tailored to our codebase.
HR and talent ops
Let’s face it — HR teams spend too much time answering the same questions. A local AI model for businesses can field the basics (leave balances, benefits, policy lookups) without involving a human.
But what gets interesting is personalization. A fine-tuned model can explain why someone’s payroll deduction changed or why they didn’t qualify for a claim in a clear, conversational language.
Local LLMs also speed up hiring. Instead of basic keyword matching, they can scan resumes for skill fit, experience depth, and certifications. L’Oréal’s AI assistant, Mya, screened over 12,000 internship applicants, collected data like visa status and availability, and helped the team hire 80 interns, saving over 200 hours of recruiting time in the process.
Document processing
Confluence docs. Jira tickets. Meeting notes. LLMs eat this stuff for breakfast.
A local model running on your internal content can summarize long pages, answer questions, or generate progress reports instantly. No more digging and no more toggling tabs.
Intellias built an LLM-powered platform for just this purpose for one of our customers. It became the single-entry point for data search and management for all company employees.
Smarter business ops
According to Gartner, AI will automate 80% of project management tasks within a decade. But if you’re using tools like Zoom AI, you’ve probably seen it start already (think meeting summaries auto generated and delivered as soon as the call ends).
One retailer we work with is taking it further: they’re training a local large language model to negotiate with vendors. It’s been trained on contracts, pricing history, and supplier behavior — so it can compare offers, counter-offer alternatives, and suggest fair terms in real time.
Step-by-step: How to set up and start running a Local LLM
Here comes the hands-on part (aka, the best part). This section covers the tools you need to run an LLM locally. If you’re looking for an easy setup with decent customization, start with Ollama. For more flexibility and low-level control, jump to llama.cpp section.
Ollama
Running LLMs locally often seems complex. We’re so accustomed to cloud solutions that setting up on-prem infrastructure can seem overwhelming. But that convenience comes at a cost: privacy — something enterprises can’t ignore.
That’s why we suggest Ollama for anyone who wants to get started with enterprise local LLMs, especially if they don’t want to deal with the technical complexities of model deployment.
Ollama may be a bit heavier on system resources than lighter frameworks like llama.cpp, but that’s a trade-off for ease of use.
Here is a simplified breakdown of the OLlama workflow:
- Install Ollama
- Run LLM
- Talk with LLM
Set up Ollama on the command line
Install Ollama
Step 1: Visit the official Ollama website and download the application. I’m using the Mac version for this tutorial.
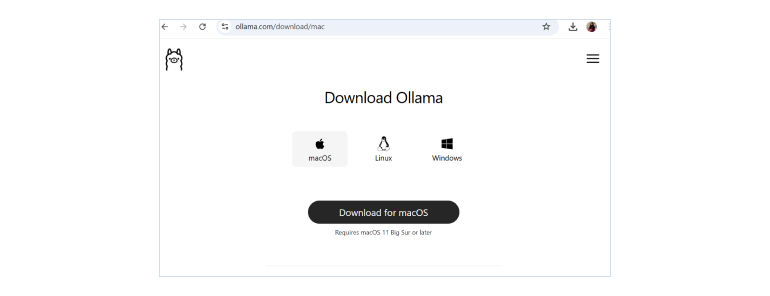
Step 2: Open the downloaded application and click “Install”.

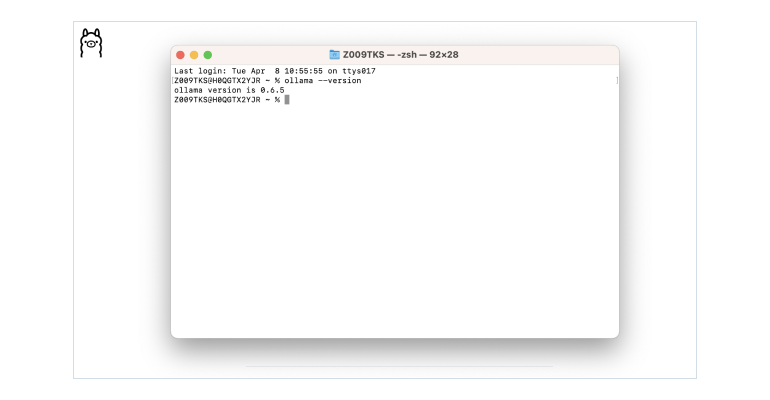
That’s it! Your machine now has Ollama installed on it. To verify the installation, open your terminal and run: `ollama –version`.
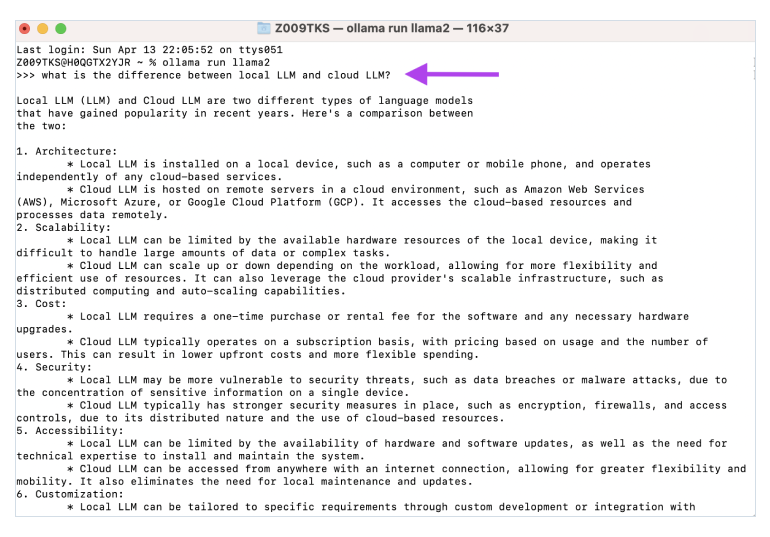
Run models in Ollama
Ollama supports a variety of powerful LLMs. Which one you choose depends on your use case and available resources. In this example, we’re using Llama from Meta. It’s lightweight, efficient, and a great starting point if you’re working with limited hardware.
Not sure which model to choose? There’s a section in this guide that breaks down some popular models and what they’re best at.
Once you’ve chosen the model, run the following command to load it from the Ollama library.
Ollama run llama2
Talk with LLM
That’s it. All the groundwork is complete, and you’re ready to start asking questions right from the terminal.
Set up Ollama web UI
You can customize LLMs on the Ollama command line. However, the tool also offers a web UI. It’s the easiest way to interact with and customize your models.
First, you’ll need Docker Desktop installed to set up the Ollama web UI. Installing Docker is pretty straightforward; just visit the Docker website, download the app, and run it. Once Docker Desktop is up and running, follow the instructions below to get started with Ollama.
Step 1: Open your terminal and run the following command to pull the latest web UI Docker image from GitHub:
docker pull ghcr.io/open-webui/open-webui:main
Step 2: Execute the `docker run` command. This will allocate the necessary system resources and environment configurations to start the container.
docker run -d -p 3000:8080 -e WEBUI_AUTH=False -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
- `-d`: Runs the container in the background
- `3000:8080`: Port 3000 on your local machine connects to port 8080 inside the container.
- `-e WEBUI_AUTH=False`: Disables authentication, so you don’t need to log in to access the web UI
- `-v open-webui:/app/backend/data`: Directory to store configurations or chat history
- `ghcr.io/open-webui/open-webui:main`: The docker image you pulled from GitHub.
Now open up Docker Desktop. Go to the Containers tab, and you’ll see a link under Port(s) — go ahead and click it.
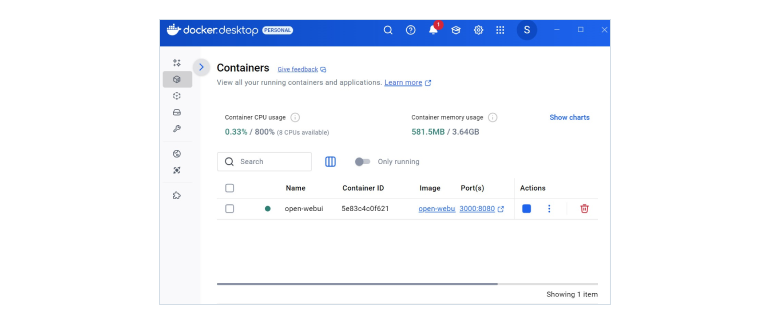
Here’s the UI that opens.
Llama.cpp
Ollama excels at performance and user-friendliness. But what if you have very limited hardware and need lightweight software? That’s where llama.cpp comes in.
It’s a C/C++ framework designed to execute LLMs with lightning speed, making it perfect for applications that demand real-time responses.
Llama.cpp offers two methods for running LLMs on your local machines:
- Clone the llama repository and run models: This offers full control over the model. You can quantize models, adjust GPU acceleration, and more.
- Llama-server: Simple and runs any pre-trained model from the extensive Hugging Face library.
Clone llama.cpp
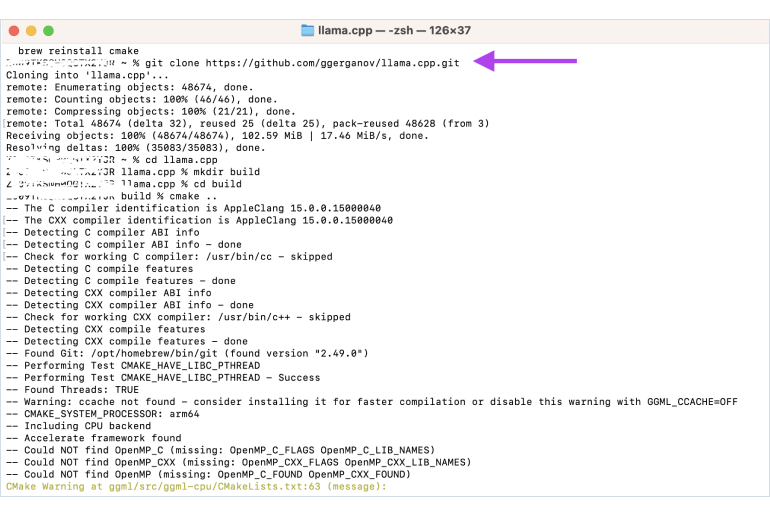
Step 1: Clone the llama.cpp repository to local using the git clone command.
git clone https://github.com/ggerganov/llama.cpp
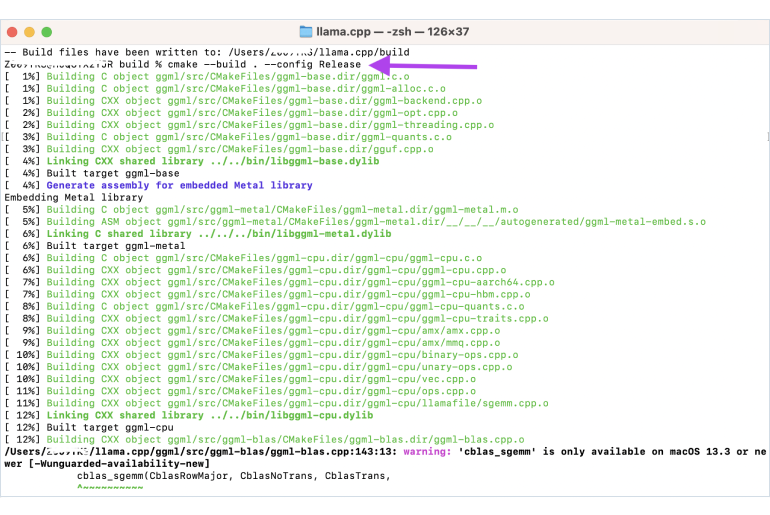
Step 2: Follow these commands to build the project using CMake.
mkdir build
cd build
cmake ..
cmake --build . --config Release
Step 3: Download the desired GGFU formatted model from the Hugging Face library. Once done, save it to a directory on your local machine. You’ll need this path while running the model in the next step.
Step 4: Run the model using the following command:
./llama-cli -m /path/to/your/model.gguf
Replace `/path/to/your/model.gguf` with the actual path to your downloaded model file.
Quantize models:
You can quantize models in llama.cpp with this syntax on the terminal: `./quantize <input-model.gguf> <output-model.gguf> <quantization-type>`
Example command: `./quantize models/llama-2-7b.gguf models/llama-2-7b-q4_0.gguf Q4_0`
To run the quantized model: `./main -m models/llama-2-7b-q4_0.gguf -p “Tell me a fun fact about space`.
llama-server
Step 1: Open your terminal and run the following command to install llama.cpp on your Mac.
brew install llama.cpp
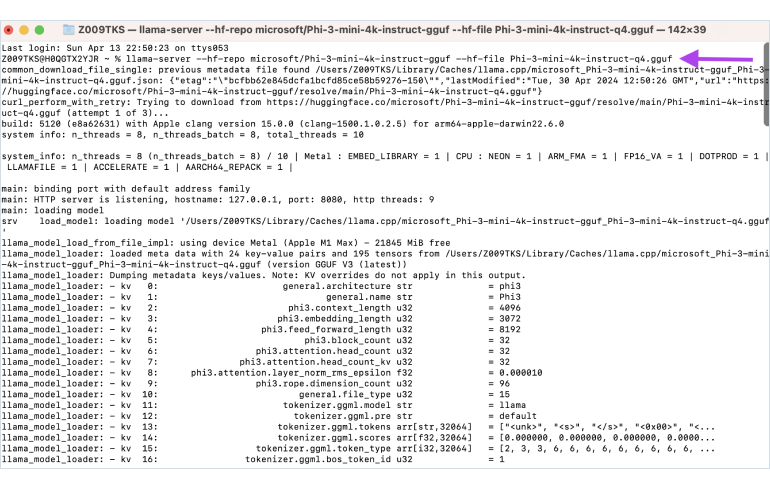
Step 2: Hugging Face hosts a vast collection of open-source models. You can use its repo ID and model file name to serve a model directly in a CLI.
Syntax:
llama-server --hf-repo <hugging-face-repo-id> --hf-file <gguf-model-name>
Find repo IDs and file names here. Sample command that starts the Microsoft Phi model:
llama-server --hf-repo microsoft/Phi-3-mini-4k-instruct-gguf --hf-file Phi-3-mini-4k-instruct-q4.gguf
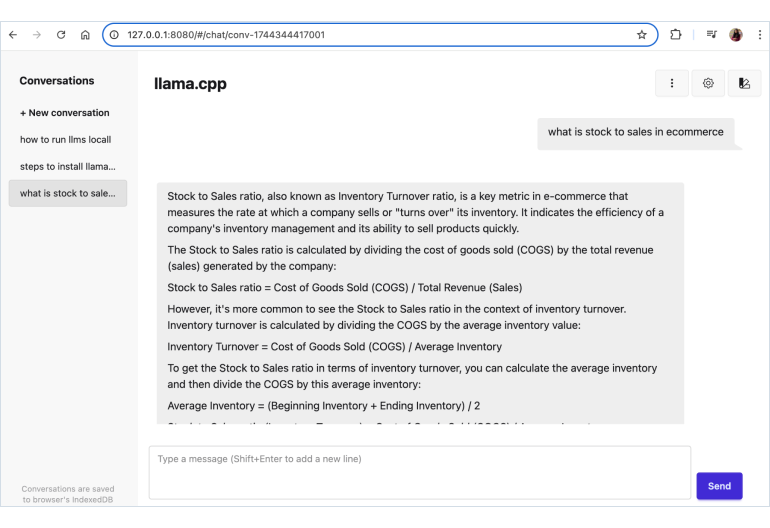
You can now interact with the model through the web UI or curl commands.
Web UI
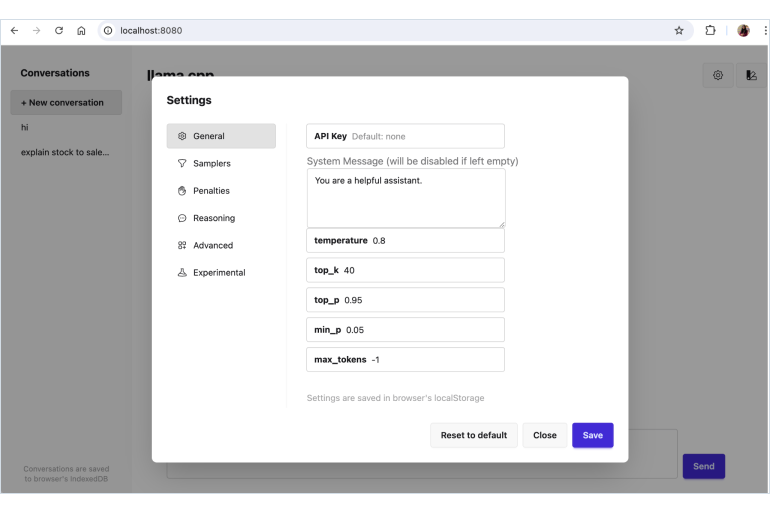
The model’s web UI is accessible at your local host: http://127.0.0.1:8080/.
Click the settings icon in the top right corner to customize the LLM.
Curl commands
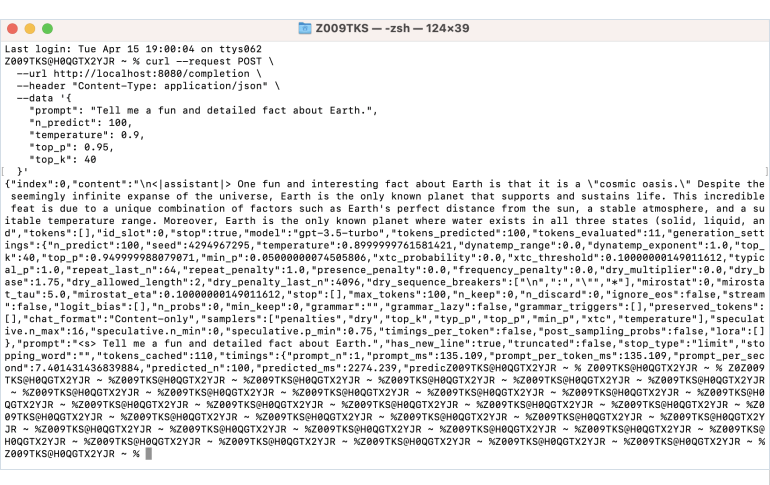
You can run this curl command directly in your terminal and get the results right there.
curl --request POST \
--url http://localhost:8080/completion \
--header "Content-Type: application/json" \
--data '{
"prompt": "Tell me a fun and detailed fact about Earth.",
"n_predict": 100,
"temperature": 0.9,
"top_p": 0.95,
"top_k": 40
}'
More ways to run an LLM locally:
Gpt4All
Gpt4All provides both a desktop app and command-line options to run LLMs locally. The interface is clean, and the setup is pretty straightforward. This tool also provides access to both local and remote models.
- Step 1: Download the application from the official page.
- Step 2: Run the downloaded installer and follow the on-screen instructions to finish the installation.
- Step 3: Open the app, select “Models” on the left menu bar, and download the desired model.
You can interact with the model by going to “Chats” on the left menu bar.
LM Studio
LM Studio provides a beautiful desktop app to run and chat with gguf-based models, backed by llama.cpp.
- Step 1: You can download the tool here.
- Step 2: Use its search function to discover any model from Hugging Face and download it.

- Step 3: Click the chat icon on the left sidebar and you’re good to start talking with the model.
Which open-source language model should you choose?
In this section, we outline key features of some popular large language models to help you choose the right model.
Llama3 – Llama3 handles complex NLP tasks. The model deeply understands the context and excels in response generation. It supports both text and image processing, and the depth and breadth make it worthwhile for research and market analysis. Llama3 is also ideal for conversational AI like chatbots or customer support personalization.
Mistral models are built for low-latency tasks where every millisecond counts. They conduct high-speed text processing, making them perfect for real-time chatbots. For instance, Mistral 3B and Mistral 8B are designed to process data faster on limited hardware, ideal for IoT and mobile applications. The Mistral family also includes Codestral and Codestral Mamba (7B), which excel at programming tasks.
Phi: Phi is a transformer-based architecture. Designed for compact devices, these models (ranging from 3.8B to 14B parameters) punch above their weight. These are especially sharp at reasoning-focused applications like solving logic problems, doing math, and following detailed instructions.
Code-gen: A Salesforce-developed model, Code-gen lets developers describe what they want in plain English and turns it into usable code.
BERT: BERT is a resource-efficient, encoder-only model. It can understand text well, but it’s inefficient at generating it. That means it’s brilliant at sentiment analysis, text classification, and research applications.
How to reduce costs and integrate enterprise local LLMs
This section is more about you: how to keep LLM costs in check and scale them into your business applications.
Reduce costs
Local LLMs aren’t as expensive as you think. Here’s how to make the most of them without going overboard on spending.
Use open source, don’t train: LLMs are costly when you train them from scratch. But your aim isn’t to build the next ChatGPT or Deepseek. You just want to use Gen AI to enhance your business operations. So, use open-source models. These models are already trained on billions of data points; you just need to tune them for your use case.
Use smaller models: Most enterprise use cases aren’t about solving general AI or building AGI (artificial general intelligence) that does everything. Typically, you need a focused, local LLM fine-tuned for a specific task, and smaller models pull their weight just fine for most of these, without eating up your compute too quickly.
RAG (Retrieval-Augmented Generation) allows your model to search instead of memorize. That means you don’t need to encode all data into your model. Instead, you can store that data in a much cheaper and more scalable system and let the model pull in only the information it needs to answer the prompts. Here’s how you can build RAG-based chatbots.
Quantization: We finally got some space to talk about quantization. It is an innovative technique for storing model parameters (weights and biases) in lower-precision data formats, such as INT8 instead of float32. That single change can cut memory usage by up to 4x.
Integrate and scale
The real goal of running a local LLM is integrating it into your business applications for everyday tasks.
Firstly, fine-tune an open-source model on your company’s specific data and deploy it on the cloud or your own data center. Cloud solutions like AWS or Google Cloud are great for scalability. For greater privacy, if you have sophisticated data centers, you can host your models there, too.
Lastly, use a Python script or FastAPI to expose your model as an API endpoint and then integrate that endpoint into your business applications.
If you want to offload the technical complexities of building or integrating local LLMs, consider Gen AI service providers like Intellias. They handle the complex parts — deployment, fine-tuning, and infrastructure management — and leave the fun part for you: chatting with LLMs.
Conclusion
Running a local LLM offers enterprises the trifecta of privacy, performance, and control. Whether you’re aiming to reduce costs, eliminate data exposure risks, or integrate scalable AI solutions powered by LLMs, local deployment is the new standard.
Want a shortcut? Our experts can help you run LLMs locally, tune them to your enterprise data, and embed them into the systems your teams use every day.


