Underwriting an insurance policy used to take weeks, but modern insurance underwriters use data analytics and artificial intelligence to write a policy in less time than it takes to brew a cup of coffee. Consider life insurance, for example. Before the advent of advanced analytics, applicants filled out lengthy forms, underwent medical exams, and waited while insurers consulted actuarial tables that generalized large populations. Today, data-driven systems can analyze electronic health records, lifestyle factors, and behavioral information in seconds, producing premiums that are more personalized and more representative of real-world risks.
This digitalization has reshaped the insurance industry. Underwriting, once viewed as a slow back-office function, has become fast, precise, and transparent. Companies now integrate structured data, such as claims histories and financial statements, with unstructured data like broker submissions, satellite images for property evaluations, and customer service transcripts. This variety of information supports stronger underwriting models, higher underwriting accuracy, and a smoother customer experience.
What is data analytics in insurance underwriting?
In the context of insurance underwriting, data analytics is the practice of applying statistical methods to data from different sources (often for predictive modeling of future events) and applying machine learning algorithms and deep learning techniques to evaluate risk, and using ML-based pricing models. Insurers have always collected detailed information—names, addresses, phone numbers, as well as income, assets, property location, and other facts that build a more accurate profile—but today they can organize and analyze it at a scale that was not possible a decade ago.
While statisticians require clean, structured insurance data to form accurate analyses, unstructured data can provide contextual insights. Combining structured and unstructured data provides a richer picture of risk and allows underwriters to predict the likelihood of future insurance claims. Data analytics models can also recommend actions, such as adjusting prices or routing cases for manual review. Furthermore, a data-driven workflow helps to prioritize tasks. With the assistance of artificial intelligence, AI agents can even take over smaller tasks and save an underwriter’s time for more complex matters.
For a complete analysis, a statistician or data analyst will want to review three different types of digitalized underwriting data:
- Structured data: Medical records, claims histories, financial statements, and any data that is stored in a predefined format.
- Unstructured data: Broker notes, inspection reports, customer interactions, and any data that is not stored in a predefined format because it is difficult to do so. Most of the data generated is unstructured data, which can provide rich contextual insights about structured data.
- External data: Connected car telematics, satellite images, climate data, and anything else that could provide additional contextual awareness.
Together, these data types support continuous underwriting models that are dynamic rather than static. With the help of different data types, underwriters can move beyond large population averages and create individualized risk assessments that improve both operational outcomes and customer satisfaction.
Traditional vs. data-driven approach to insurance underwriting
The traditional underwriting process was slow, manual, and built on a limited set of information. Applications often required weeks of filling out paperwork and waiting for verification, with outcomes heavily dependent on the judgment of individual underwriters. Risk assessment, meanwhile, relied on historical averages and broad categories. This meant that many customers received standardized pricing that did not reflect their true risk profile.
Using data and analytics in insurance underwriting results in customized policies that are fairer and better protect policyholders. And along with the policy and price being better, so is the underwriting process. Underwriting engines automate policy validation, risk-segmentation models can distinguish between applicants who once looked identical, and digitized underwriting processes reduce errors while improving efficiency.
Some of the clearest contrasts between manual and automated underwriting include:
- Speed of decision-making: Manual reviews that once took weeks are now completed in minutes.
- Granularity of risk: Broad demographic pools are replaced with detailed risk-segmentation models that account for dozens of variables.
- Customer experience: Vague processes and long wait times have been replaced by transparent pre-underwriting and underwriting criteria and personalized offers.
Traditional approach vs. data analytics in insurance underwriting
| Dimension | Traditional approach | Data-driven approach |
|---|---|---|
| Decision speed | Weeks of manual checks and documentation | Checks in minutes, with automation and AI models supporting real-time validation |
| Risk segmentation | Broad categories built on limited factors | Detailed segmentation using structured and unstructured data |
| Customer experience | Vague process and standardized pricing | Transparent criteria, personalized pricing, and rapid responses |
Insurance companies continue to invest in data and analytics underwriting capabilities. Legacy practices cannot keep pace with growing customer expectations or risk complexity, which is why insurance companies continue to add data and analytics capabilities to underwriting. By adopting data-driven methods, carriers improve underwriting performance, strengthen risk assessment, and deliver an experience that aligns with the expectations of today’s tech-savvy policyholders.
Technologies for data analytics in insurance underwriting
The technologies shaping underwriting are best understood as lenses that bring new layers of detail into focus. Where an underwriter once worked with a handful of files and a medical exam, they now have access to tools that can process signals from dozens of different channels and draw them together into one coherent view.
Technologies used for data analysis in insurance underwriting
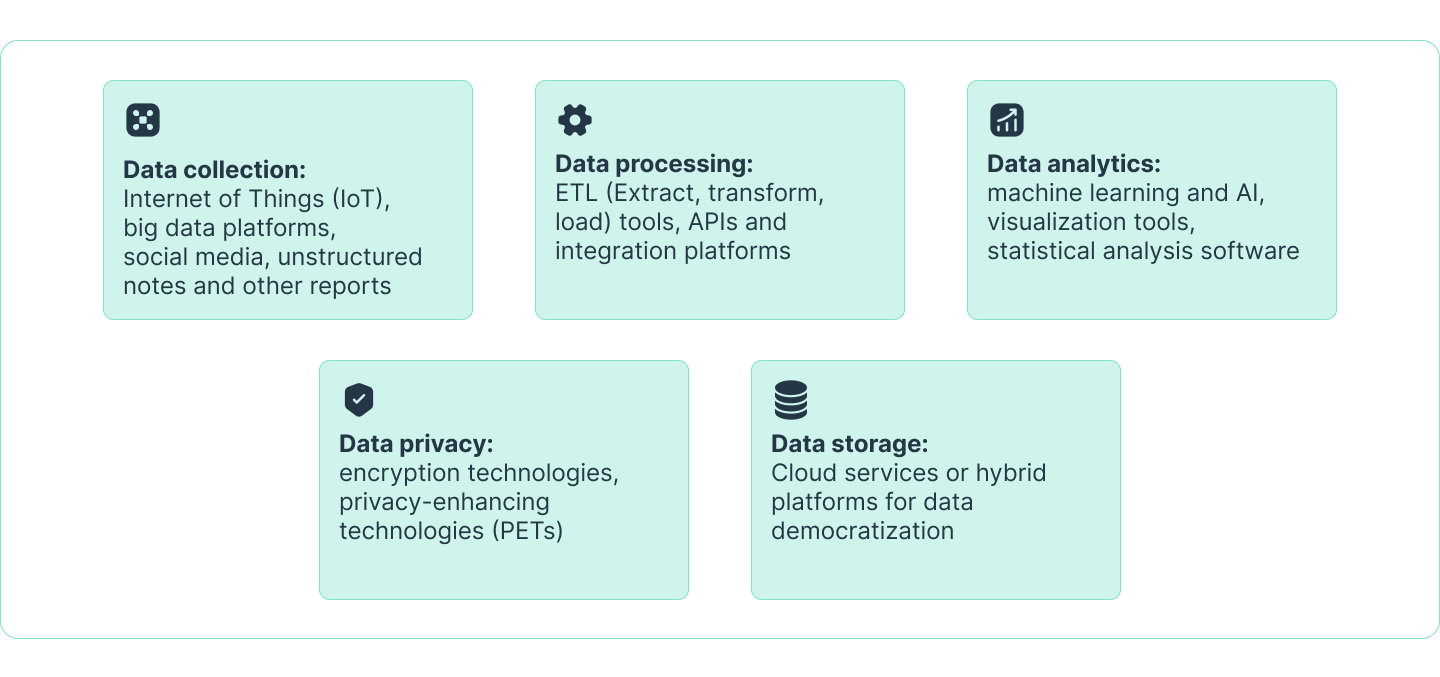
Machine learning models are the most widely recognized of these tools. Data scientists have trained ML models with millions of historical insurance claims and customer records. This enables the models to find and highlight subtle patterns that people would struggle to see on their own. For example, a data model might reveal that certain property features increase the likelihood of fire damage, or that a particular spending pattern is associated with lower health risks. Property and casualty (P&C) insurers use ML not to replace human intelligence but to enrich it with evidence drawn from a much deeper pool of information.
Natural language processing (NLP) has also enabled underwriters to generate policies faster. The insurance industry has always collected broker notes, adjuster reports, and inspection files. However, many of these documents ended up buried in storage because they were too hard to search. Now, NLP-powered systems can quickly search these records, identify relevant details, and convert them into structured data. With the help of NLP, a broker’s submission can be analyzed next to a claims record or, for P&C underwriting, geospatial data.
Connected devices bring a real-time dimension. Telematics in vehicles provides details to insurance companies about how someone drives: how fast they accelerate, how often they brake, and whether they drive mostly at night or during the day. Similarly, smart sensors in homes and offices monitor water use, temperature changes, and equipment maintenance. Geospatial and climate data complete the picture. Satellite images can detect roof damage or vegetation growth, while predictive climate models estimate the likelihood of weather events, such as flooding or wildfire.
Individually, each of these technologies adds detail to the analysis. Together, they form a web of information that changes how insurers view risk exposure. A single application may use dozens of data points, each tested against years of previous data and analyzed by systems designed to refine their accuracy with every cycle. The result is a process that produces a risk profile far more nuanced than what older underwriting methods could ever deliver.
Benefits of data analytics in insurance underwriting
Faster delivery is the first benefit of using data analytics for underwriting. Customers no longer need to wait weeks for an answer. Applications move through systems in minutes, so customers get quotes before their attention drifts. This reduces the number of people who abandon the application process entirely, resulting in more policies being closed.
Data domains available to insurance underwriters through analytics
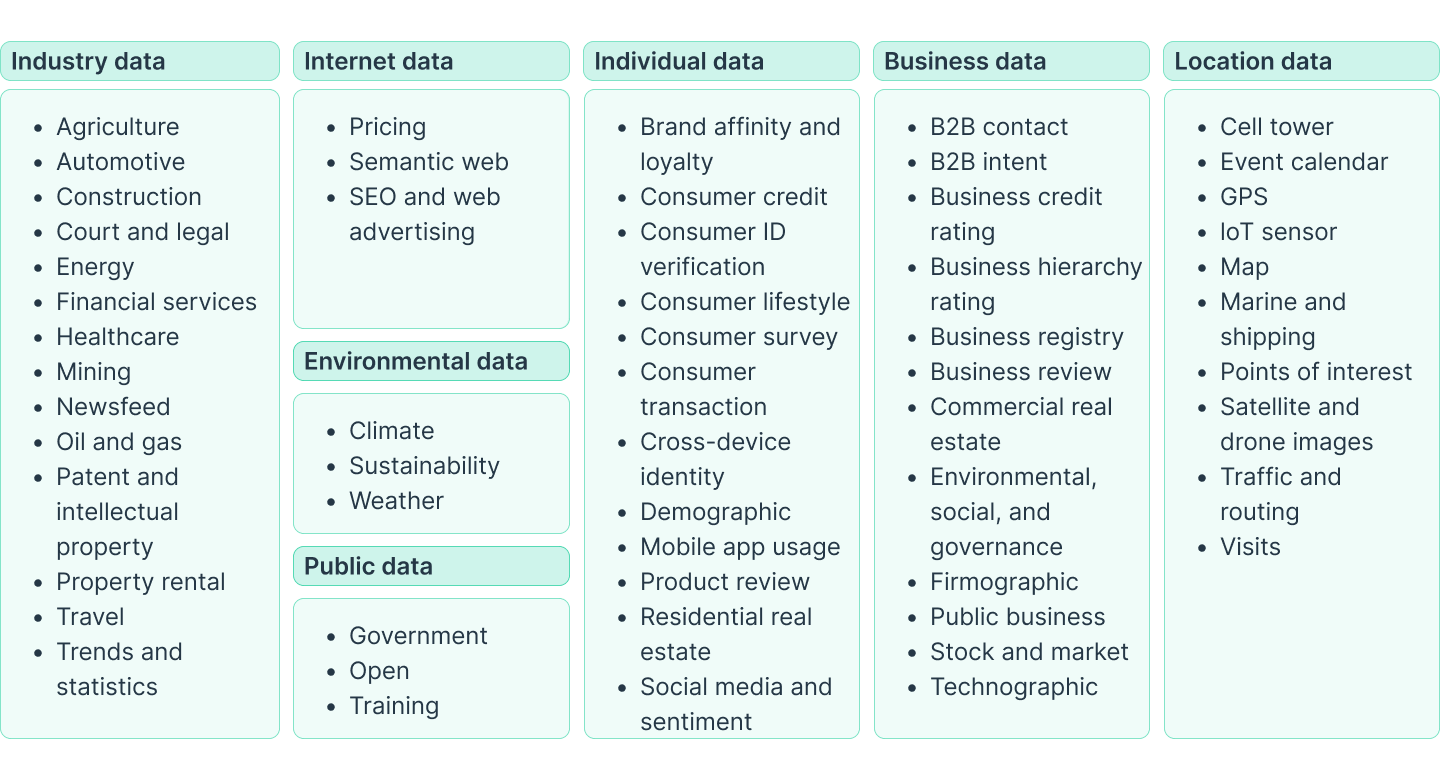
Source: McKinsey & Company | How data and analytics are redefining excellence in P&C underwriting
Yet speed is only part of the story. Accuracy has improved, too. Data analytics allows underwriters to align pricing with the real characteristics of a customer or property rather than applying a generalized rate to everyone in a demographic bucket. Just as a careful driver pays a premium that reflects safe behavior, a homeowner who invests in protective measures sees that investment recognized. Policies begin to feel more personal, and trust grows when customers can see the link between their actions and their pricing.
The operational side of underwriting benefits just as much. Claims processing automation takes over repetitive checks and data validation, leaving underwriters with the time and space to focus on cases where expertise matters most. Fraud detection is also more effective, since patterns across claims or submissions can be flagged instantly by models scanning thousands of transactions.
These improvements ripple outward:
- Customers gain faster responses, clearer pricing, and a stronger sense that they are being treated as individuals.
- Insurers build healthier portfolios with lower loss ratios and more efficient operations.
- Underwriters themselves find more meaning in their work, spending less time moving paper and more time applying judgment to complex underwriting decisions.
Transparency is another benefit worth noting. Modern underwriting systems generate audit trails that show which data was used, how a model reached its conclusions, and what steps an analyst or underwriter took next. Regulators appreciate this visibility into the underwriting process, and customers feel more comfortable knowing that decisions can be explained.
Taken together, these benefits set a higher standard for the entire industry. In the modern insurance marketplace, underwriting excellence occurs by combining speed, accuracy, and transparency. Each improvement strengthens the others, producing a system that is faster, smarter, and ultimately more resilient.
Change management for data analytics in insurance underwriting
Technology does not spontaneously generate individualized insurance policies. Insurers who approach digital underwriting transformation as an organizational effort that aligns people, processes, and culture with new tools are having the most success in the era of personalization.
Collaboration is a central requirement. Underwriters, data scientists, and technology specialists should join in the transformation process early to develop underwriting models that reflect realistic workflows for everyday use. A model designed without the input of underwriters may produce elegant policies not acceptable for actual practice, and tools designed without technical expertise may never be able to scale with growth. The best outcomes happen when all stakeholders share knowledge from the start.
Infrastructure plays a role, too. Legacy systems were not built to handle live data feeds or rapid updates to models. Insurers that successfully implement data analytics invest in cloud platforms and flexible, integrated data environments that adapt to changing conditions.
Culture is often the hardest barrier to overcome. Moving to a data-driven process means that underwriters must trust a model’s recommendations, and that trust comes only with training, transparency, and experience. Reskilling programs may help professionals understand how data models work and how to interpret their results. Yet, it is up to management to ensure the culture is ready for change. Without cultural readiness, even the most advanced technology will struggle to gain traction. Insurers that approach data analytics as an ongoing commitment rather than a one-time project create an environment where technology, talent, and data governance advance in parallel. They prepare their underwriting functions not only for the current wave of change but also for the demands that will emerge in years to come.
Challenges and ethics of data analytics in insurance underwriting
The rapid adoption of data analytics in insurance underwriting has brought undeniable benefits, but it has also raised challenges that demand equal attention. As technology expands the amount of information available to underwriters and enables them to respond at increasing speed, each new data source or model introduces questions about reliability, fairness, and responsibility. The organizations that succeed are those that take these questions seriously rather than trivializing them.
One of the most pressing concerns is the quality of information for training data analytics models. Legacy systems often contain fragmented or inconsistent records, and real-time data streams from devices such as IoT sensors can generate noise alongside valuable signals. Without strong governance, even the most advanced model can lead underwriters astray. At the same time, customers and regulators are increasingly focused on how personal data is collected and used. Health records, driving behavior data, and household monitoring data are deeply sensitive, and mishandling such data erodes trust.
Equally important are the ethical dimensions. Predictive analytics models can unintentionally generate the biases present in their training data, leading to unfair treatment of certain groups. Black-box AI algorithms may deliver statistically sound results but leave customers and regulators frustrated when the reasoning behind a decision cannot be explained. Addressing these issues requires a combination of technical safeguards and cultural commitment inside the organization.
Among the greatest concerns are:
- Data quality and integration: Creating a reliable, unified view of risk from diverse systems and feeds.
- Privacy and security: Protecting sensitive health, financial, and behavioral information.
- Bias and fairness: Eliminating biases to prevent algorithms from reinforcing inequities.
- Explainability: Ensuring that information produced by models can be interpreted and that decisions are justifiable.
- Regulatory alignment: Adapting to changing standards for transparency and consumer protection.
These challenges are not barriers to progress; rather, overcoming them is a precondition for lasting success. Insurers that face them directly will be in a better position to maintain trust, satisfy regulators, and build underwriting practices that endure.
Future trends for data analytics in insurance underwriting
The pace of change in insurance underwriting is expected to accelerate rather than slow. As data models mature and data streams become more accessible, the role of big data analytics in the insurance sector will extend beyond efficiency, affecting the nature of insurance products and the relationships between underwriters and customers. These trends will see business analytics woven into the fabric of insurance operations:
- Real-time monitoring will become imperative. Instead of underwriting as a single event at the beginning of a policy, insurers are exploring continuous assessment, where information from connected cars, smart homes, and wearable devices is used to adjust risk profiles over time. This makes coverage more flexible and allows pricing to reflect current behavior and conditions rather than historical averages. Customers are beginning to expect this kind of responsiveness, and carriers that deliver it will stand apart.
- AI will evolve. Beyond the scope of predictive intelligence and prescriptive analytics, AI agents are being developed to act as partners for underwriters. They can automatically gather data from multiple systems, find gaps, and suggest next actions. These agents are not replacements for expertise but companions that can manage the heavy lifting necessitated by large volumes of complex data. The underwriter of the future may spend less time searching for information and more time applying judgment to strategy and complex risks.
- Regulation will shape the trajectory. As models grow more sophisticated, expectations for transparency will rise. Insurance underwriters who can clearly explain their methods while demonstrating that their models promote fairness and safeguard individual privacy will gain both regulators’ confidence and customers’ trust. In this way, the future of underwriting is not only technical but also ethical, requiring companies to balance the cost of innovation with the return of accountability.
What emerges is a picture of underwriting as a living system: dynamic, adaptive, and closely tied to the realities of individual behavior and global change. The companies that embrace this evolution will set the standard for the industry in the decade ahead.
The era of AI agents is here. Contact Intellias to learn how data analytics empowers insurance companies with next-generation underwriting techniques.


